Nebius AI Review: Does This Cloud GPU Platform Hit the Mark?

When it comes to AI workloads, choosing the right cloud GPU provider can make or break your project’s performance. Nebius AI promises high-speed GPUs, competitive pricing, and a solid infrastructure. But does it live up to the hype?
In this review, I’ll dive into everything that matters—pricing, GPU models, storage, networking, support, and ease of use. By the end, you’ll know whether Nebius AI is worth your investment or if you should look elsewhere.
Table of Contents
Nebius AI: Quick Verdict
Nebius AI offers impressive infrastructure and modern GPU models at competitive prices. However, its overall appeal depends on specific workloads. While it’s perfect for AI training and large-scale ML tasks, smaller projects or those with simpler needs might not find enough value.
Who it’s for:
- AI/ML researchers
- Developers needing large-scale GPU resources
Who it’s not for:
- Casual users or small-scale projects with minimal computational needs
Nebius AI Feature Overview
| Feature | Details |
| GPU Models | Latest NVIDIA A100, H100, V100 available |
| Pricing | Pay-as-you-go and reserved instances, competitive pricing |
| Storage | SSD-backed block storage, expandable options |
| Networking | High-speed networking with low latency |
| Support | 24/7 customer support via chat and ticket system |
| Ease of Use | Intuitive UI with API access for automation |
Nebius AI: Pros and Cons
Pros:
- Modern GPU models (A100, H100)
- Flexible pricing plans
- Excellent infrastructure scalability
- High-speed, low-latency networking
Cons:
- Not beginner-friendly
- Complex pricing structure for long-term use
- Limited support for legacy workloads
Deep Dive: Nebius AI Key Features
1. GPU Models
When choosing a cloud GPU provider, the available GPU models directly impact your workload performance and cost efficiency. Nebius AI stands out by offering a range of NVIDIA GPUs, specifically tailored for AI, machine learning (ML), and high-performance computing (HPC) tasks. As of now, Nebius provides access to the latest and most powerful models, including NVIDIA A100, H100, and V100. Let’s break down each model, their features, and how they fit different use cases.
NVIDIA A100 – The Versatile Powerhouse
The NVIDIA A100 is one of the most widely used GPUs for AI and ML tasks. Built on the Ampere architecture, it delivers exceptional performance for both training and inference workloads. With up to 80 GB of high-bandwidth memory (HBM2e) and support for multi-instance GPU (MIG) technology, it can efficiently handle multiple workloads on a single GPU.
Key highlights of the A100:
- FP64 performance: Ideal for scientific computing and simulations.
- Tensor Cores: Provide accelerated matrix operations, making it perfect for deep learning models.
- Scalability: Supports NVLink and NVSwitch for multi-GPU setups.
This model is suitable for large-scale training jobs, complex neural networks, and advanced research applications. Whether you’re working on image recognition, natural language processing (NLP), or recommendation systems, the A100 provides the performance and flexibility you need.
NVIDIA H100 – Cutting-Edge AI Acceleration
The H100 is NVIDIA’s next-generation GPU, designed to push the boundaries of AI and HPC workloads. Built on the Hopper architecture, it features HBM3 memory and introduces the new Transformer Engine, which accelerates transformer-based models used in NLP and generative AI.
Why the H100 stands out:
- FP8 and FP16 performance: Provides faster training and inference for large language models (LLMs) while consuming less power.
- Transformer Engine: Specifically optimized for NLP tasks, making it the go-to choice for anyone working on chatbots, translation systems, and generative models like GPT.
- Higher bandwidth: Thanks to HBM3 memory, the H100 offers significantly faster data throughput compared to previous models.
If your workload involves massive datasets, complex simulations, or LLM training, the H100 can deliver unmatched speed and efficiency. Its higher price tag is justified by the significant reduction in time-to-results for demanding tasks.
NVIDIA V100 – The Veteran Performer
Though older than the A100 and H100, the V100 still holds relevance for many AI and HPC applications. Built on the Volta architecture, it introduced Tensor Cores for the first time, making it a pioneer in accelerating deep learning tasks. It offers 16 or 32 GB of HBM2 memory, ensuring reliable performance for both training and inference.
Why you might choose the V100:
- Proven reliability: Many existing frameworks and workflows are optimized for the V100.
- Cost-effectiveness: While not as powerful as the A100 or H100, the V100 is more affordable and can still handle medium-to-large models efficiently.
- Good for inference: For inference-heavy workloads that don’t require the latest technology, the V100 is a budget-friendly option.
Which GPU Should You Choose?
The right GPU model depends on your specific use case. Here’s a quick guideline:
- NVIDIA H100: Ideal for cutting-edge research, generative AI, large language models, and advanced NLP tasks.
- NVIDIA A100: Best for general AI/ML workloads, including image classification, object detection, and recommendation systems.
- NVIDIA V100: A great choice for budget-conscious teams working on mid-sized models or inference workloads.
Performance Benchmarking
While Nebius AI doesn’t publicly share detailed performance benchmarks, user reports indicate impressive results across all models, especially for distributed training. The A100 and H100 excel in large multi-GPU environments, thanks to NVLink and NVSwitch support. Users running multi-node ML training have noted significant improvements in speed and efficiency compared to other providers.
For example, when training a ResNet-50 model on the A100, users can expect up to 2-3x faster performance compared to older models like the V100. The H100 further accelerates this with its advanced architecture and Transformer Engine.
Multi-GPU and Scalability Options
Nebius AI supports multi-GPU instances, allowing users to scale their workloads horizontally. Whether you’re working on parallel training, hyperparameter tuning, or ensemble models, the platform ensures seamless scalability with minimal latency. The GPUs can be interconnected using NVLink, ensuring high-speed communication between devices.
This is particularly beneficial for tasks requiring massive computational power, such as GAN training, climate modeling, and biological simulations.
Nebius AI’s offering of NVIDIA’s latest GPUs ensures that users have access to cutting-edge hardware for all kinds of AI and HPC tasks. With support for A100, H100, and V100 models, the platform caters to a wide range of use cases, from budget-conscious inference jobs to high-end AI research requiring bleeding-edge performance.
Unlock savings of up to 30% by reserving GPUs long-term on CUDO Compute, ensuring cost efficiency without sacrificing performance or scalability. Sign up now!
2. Pricing
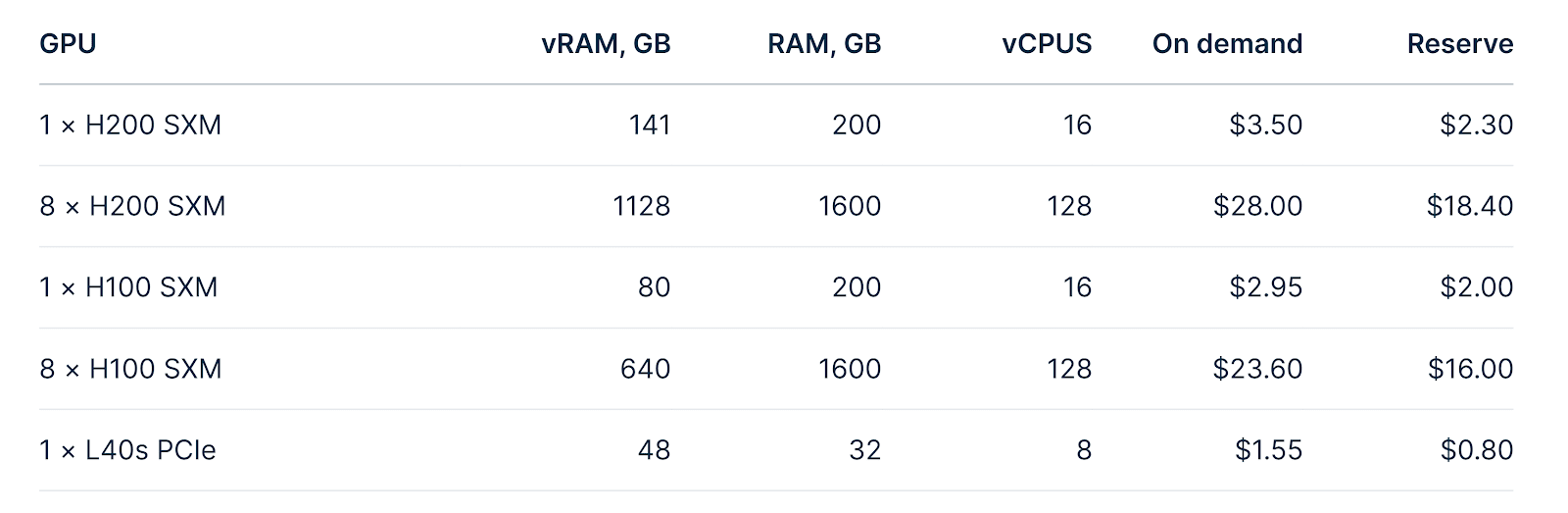
Nebius AI offers a flexible and competitive pricing structure designed to accommodate various AI and machine learning (ML) workloads. With multiple GPU models available, the pricing options include on-demand rates, reserved plans, and a special Explorer Tier for new users. Below is a comparison table highlighting key pricing details for different GPUs:
| GPU Model | VRAM (GB) | RAM (GB) | vCPUs | On-Demand Price | Reserved Price |
| NVIDIA H200 SXM | 141 | 200 | 16 | $3.50/hour | $2.30/hour |
| 8 × NVIDIA H200 SXM | 1128 | 1600 | 128 | $28.00/hour | $18.40/hour |
| NVIDIA H100 SXM | 80 | 200 | 16 | $2.95/hour | $2.00/hour |
| 8 × NVIDIA H100 SXM | 640 | 1600 | 128 | $23.60/hour | $16.00/hour |
| NVIDIA L40S PCIe | 48 | 32 | 8 | $1.55/hour | $0.80/hour |
Flexible Payment Options
Nebius AI supports multiple payment models to cater to both corporate and personal users. You can choose from:
- On-Demand (Pay-as-You-Go): Ideal for short-term or variable workloads.
- Reserved Plans: Offers significant savings when you commit to resource usage for 3 months to 3 years.
- Explorer Tier: A special introductory offer with discounted rates of $1.50/hour for H100 GPUs for the first 1,000 GPU hours/month until March 31, 2025.
Networking and Storage Costs
- Public IP address: Free
- Egress traffic: Free within the same region
- Shared Filesystem SSD: $0.16/GiB per month
- Object Storage: $0.0147/GiB per month
Nebius AI’s pricing structure is transparent and competitive, making it a great choice for teams looking to balance performance with cost-efficiency. The combination of commitment discounts, flexible payment models, and free networking perks further enhances its appeal.
3. Storage
Nebius AI offers a highly scalable storage solution tailored for machine learning models and AI workloads. Their AI-centric cloud platform is designed to support everything from simple websites to complex model training tasks. Whether you’re running virtual machines for AI experiments or deploying managed Kubernetes clusters for production workloads, Nebius ensures high availability and maximum performance.
The storage options include:
- Shared Filesystem SSD: Ideal for workloads requiring fast access to large datasets, priced at $0.16/GiB per month.
- Object Storage: A cost-effective solution for storing unstructured data like machine learning models, priced at $0.0147/GiB per month.
This comprehensive suite of storage services integrates seamlessly with Nebius’ cloud infrastructure, enabling users from various industries to build, train, and deploy models at scale. Compared to providers like AWS or Google Cloud, Nebius AI focuses on offering specialized storage for AI, with free ingress and egress traffic within the same region to minimize costs.
Additionally, users can rely on Nebius’ dedicated engineer support for setting up and optimizing their storage environment. Whether you need high-speed storage for training large models or cost-effective options for archiving data, Nebius ensures flexibility and reliability for every workload. This makes it a compelling choice for businesses seeking efficient and affordable AI infrastructure solutions.
Deploy NVIDIA H100 and H200 GPUs on CUDO Compute, offering top-tier memory bandwidth ideal for intensive deep learning and generative AI projects. Sign up now!
4. Networking
Nebius AI’s networking capabilities are designed to ensure that users can seamlessly connect, transfer, and manage data without bottlenecks, supporting high-performance workloads in AI and machine learning applications. With the power of dedicated infrastructure, Nebius guarantees a reliable and fast networking environment for customers.
A standout feature is their free egress, ingress, and public IP address services, which can significantly lower the cost of running AI and machine learning models in the cloud. Many competitors charge for these services, but Nebius provides these essential networking features at no extra cost. This can be especially helpful when managing large-scale machine learning projects, where constant data flow is required between virtual machines, storage, and external systems.
Additionally, Nebius AI provides robust networking that supports high-speed communication between virtual machines. The ability to create private networks with private IP addresses enhances security and allows for better control over traffic routing within their cloud infrastructure. This feature is ideal for enterprises working on sensitive AI projects where privacy and security are paramount.
In terms of scalability, Nebius offers flexible networking options that make it easy to scale resources as your AI project grows. Whether you’re running small models or large-scale distributed machine learning algorithms, their network can handle it efficiently. The infrastructure also supports managed Kubernetes, making it easy to deploy and manage containerized workloads.
Overall, Nebius AI’s networking is built with performance and cost-efficiency in mind, making it an excellent choice for AI teams and organizations in various industries looking for reliable cloud infrastructure for their machine learning projects.
5. Customer Support
Nebius AI offers comprehensive customer support to ensure a smooth experience for users, whether they are deploying machine learning models or managing AI infrastructure. Their support structure is built around responsiveness, expertise, and flexibility to meet the unique needs of each customer.
One of the key highlights is their dedicated engineering support, which is available for both individuals and corporate users. This tailored support allows customers to receive assistance with specific technical issues, configurations, or optimizations related to their AI projects. Whether you are troubleshooting a specific problem or looking for advice on improving model training, Nebius AI’s engineers are on hand to help.
In addition to the personalized engineering support, Nebius offers a self-service portal that provides users with easy access to documentation, FAQs, and troubleshooting guides. This resource-rich portal allows users to find solutions to common issues quickly and autonomously, saving time and reducing dependency on direct support.
The customer support team is highly responsive, with multiple channels for reaching out, including live chat and email support. The response times are generally fast, ensuring minimal downtime for projects that require constant attention, like those in AI research and development.
Nebius also offers proactive customer support for users on the Explorer Tier, where they provide more hands-on assistance to AI enthusiasts starting their first projects. This proactive support can be a game-changer for smaller teams or independent developers who may not have in-depth knowledge of AI cloud environments.
6. Ease of Use
Nebius AI stands out for its user-friendly platform, designed to make AI infrastructure and model deployment accessible to both novice and advanced users. Whether you’re working on machine learning models, managing virtual machines, or running experiments, the platform’s ease of use is evident at every step.
The self-service console is one of the most significant features, allowing users to quickly provision resources like GPUs, storage, and virtual machines without needing deep technical knowledge. This intuitive interface guides users through setting up their environment, launching AI workloads, and accessing the necessary tools for model training and experimentation.
Nebius AI’s platform is highly customizable, yet it doesn’t overwhelm users with complexity. For those just starting out, the platform offers simplified workflows, while more advanced users can dive into configuration options for fine-tuning performance and optimizing workflows. This flexibility makes it an excellent choice for a wide range of users, from startups to large enterprises.
Additionally, the Nebius Explorer Tier is designed with simplicity in mind, offering an entry-level pricing structure that lets users experiment with AI models at an affordable rate. With instant access to NVIDIA H100 Tensor Core GPUs and no complicated setup requirements, the platform is perfect for AI enthusiasts and developers who are just beginning their journey.
The platform’s speed and reliability further enhance its ease of use. With the quick deployment of virtual machines and cloud resources, users can focus on what matters most—building and scaling machine learning models—without worrying about infrastructure management. This seamless experience is a key reason Nebius AI has become a preferred choice for many in the AI and machine learning community.
Final Thoughts: Should You Go for Nebius AI?
Nebius AI excels in providing robust cloud GPU services for serious AI/ML practitioners. It offers great hardware, scalability, and flexibility. However, the steep learning curve and complex pricing might deter smaller teams or beginners.
If you need cutting-edge GPUs and value performance over simplicity, Nebius AI is a solid choice.