RunPod vs Modal: How These Cloud Solutions Stack Up for AI Developers
Finding the right platform to run your AI workloads isn’t just about performance—it’s about the entire user experience. That’s where the RunPod vs Modal debate comes in. Both platforms promise to make deploying machine learning (ML) models in the cloud easier, faster, and more cost-effective.
RunPod boasts a globally distributed GPU cloud that feels as seamless as working locally, with instant hot-reloading and a variety of ready-to-use templates. On the flip side, Modal focuses on scaling production workloads with an optimized developer experience and advanced infrastructure like a GPU-aware scheduler. So, which one should you choose? Let’s break down the key differences and figure out which one’s the better fit for your ML needs.
Table of Contents
Runpod vs Modal: The Main Difference
RunPod offers a wider variety of GPU models and hourly pricing, making it cost-effective for long-running tasks. Modal, on the other hand, focuses on fewer high-performance GPUs with per-second billing, ideal for short, scalable tasks in a serverless infrastructure.
Affiliate Disclosure
We prioritize transparency with our readers. If you purchase through our affiliate links, we may earn a commission at no additional cost to you. These commissions enable us to provide independent, high-quality content to our readers. We only recommend products and services that we personally use or have thoroughly researched and believe will add value to our audience.
GPU Compute Comparison
Below, we’ll dive into a detailed comparison of the two providers, looking at their GPU resources, architecture, pricing, and various other factors. This should help you make an informed decision on which provider to choose based on your specific needs—whether that’s training large language models, running Stable Diffusion, deploying custom models, or managing GPU clusters for scaling AI models.
Looking for affordable, high-performance GPUs? CUDO Compute provides on-demand rentals for top-tier NVIDIA and AMD GPUs. Sign up now!
To learn more about CUDO Compute, kindly watch the following video:
Overview of GPU Instances and Availability
Both RunPod and Modal offer a variety of GPU instances tailored for different workloads. RunPod boasts a more extensive selection of NVIDIA and AMD GPUs, providing GPU resources across various price points. Modal, on the other hand, focuses on fewer, high-performance NVIDIA GPUs like the A100 and H100. Let’s explore the GPU models in more detail.
RunPod GPU Models and Pricing
RunPod offers a robust selection of GPUs that cover a wide range of performance needs. Whether you’re looking for cost-effective options for small-scale workloads or powerful GPUs for extensive machine learning training, RunPod has something for everyone.
MI300X (AMD):
The MI300X is a powerhouse designed specifically for massive AI training workloads. With an impressive 192 GB VRAM and 283 GB RAM, it can handle the most demanding tasks that require extreme memory and processing capabilities.
Featuring 24 virtual CPUs, this GPU excels in parallel processing, making it particularly suited for training large language models like GPT.
Its secure cloud infrastructure ensures that sensitive data remains protected while you leverage its capabilities. Ideal for enterprises or researchers working on cutting-edge AI applications, the MI300X allows you to push the boundaries of what’s possible in AI training and experimentation.
Whether you’re developing complex algorithms or running extensive simulations, this GPU provides the horsepower you need.
H100 PCIe (NVIDIA):
The H100 PCIe stands out for its exceptional efficiency in high-throughput tasks, particularly in machine learning inference. Equipped with 80 GB VRAM, 176 GB RAM, and 16 virtual CPUs, this model is engineered to handle large language models and complex AI computations effectively.
Priced at $2.69/hr in the Community Cloud, it offers a compelling balance between cost and performance, making it a go-to choice for developers and data scientists. Its architecture is optimized for AI workloads, enabling faster training times and reduced latency during inference.
Whether you’re working on real-time AI applications or processing vast datasets, the H100 PCIe delivers the performance required to keep your projects moving forward seamlessly.
A100 PCIe (NVIDIA):
The A100 PCIe is a highly sought-after GPU for various machine learning tasks, boasting 80 GB of VRAM, 83 GB RAM, and 8 virtual CPUs.
Starting at $1.19/hr in the Community Cloud, it provides excellent performance without reaching the price tag of the top-tier H100. This makes it an ideal choice for teams that need substantial GPU power but may not require the absolute highest performance levels.
It’s particularly well-suited for training and fine-tuning models in natural language processing, image recognition, and other machine-learning applications. Its flexibility allows developers to optimize workflows while managing costs effectively, making the A100 PCIe a popular choice for startups and established companies alike.
RTX A5000 (NVIDIA):
The RTX A5000 offers a great entry point for users venturing into GPU workloads, priced affordably at $0.22/hr in the Community Cloud. With 24 GB of VRAM, 24 GB of RAM, and 4 virtual CPUs, this GPU is well-suited for smaller models and light workloads.
It’s perfect for developers just starting with machine learning or those working on projects that don’t require extreme processing power. The RTX A5000 can efficiently handle tasks like data visualization, 3D rendering, and even some machine learning inference.
This makes it an attractive option for freelancers, students, or small businesses looking to experiment with GPU computing without breaking the bank.
RTX 3090 (NVIDIA):
The RTX 3090 is another budget-friendly option, priced similarly to the A5000 at $0.22/hr in the Community Cloud. With 24 GB of VRAM, 24 GB of RAM, and 4 virtual CPUs, it provides solid performance for a variety of tasks.
This GPU is particularly well-suited for running applications like Stable Diffusion or executing small-to-medium machine learning inference tasks. Its robust architecture allows it to perform well in scenarios that require a decent amount of computation without the high costs associated with more powerful GPUs.
Ideal for hobbyists or developers looking to explore AI and machine learning projects, the RTX 3090 offers a reliable balance of performance and affordability.
RunPod’s variety gives users a flexible range of GPUs to choose from, making it suitable for startups, academic institutions, and enterprises with varied needs. From running AI models to scaling GPU clusters, RunPod offers the right instance for every workload.
Enhance your AI and machine learning initiatives with CUDO Compute’s powerful cloud GPUs. Start scaling your projects today— Sign up now!
Modal GPU Models and Pricing
Modal keeps it simple by focusing on a few high-performance GPU models but with competitive pricing and a serverless infrastructure designed to scale automatically with demand. Here are some of the key GPUs they offer:
H100 (NVIDIA):
The H100 is a leading-edge GPU specifically designed to tackle demanding AI workloads with remarkable efficiency. Priced at $0.002125 per second (or $7.65 per hour), this powerhouse excels in deep learning applications and large-scale machine learning training.
With its substantial VRAM, it can handle vast datasets and complex models seamlessly, making it an ideal choice for developers working on natural language processing (NLP), image recognition, and other advanced AI tasks. The H100’s architecture is optimized for high throughput and low latency, enabling quick inference times for real-time applications.
Organizations focusing on AI innovation will find the H100 invaluable for accelerating research, developing new algorithms, and deploying scalable AI solutions, ensuring a competitive edge in their respective fields.
A100 80 GB (NVIDIA):
The A100 80 GB is a top-tier GPU that offers excellent performance for various machine learning tasks, priced at $0.001553 per second (or $5.59 per hour).
While slightly less powerful than the H100, it remains a robust choice for model training, particularly in areas like natural language processing and image generation. Its generous VRAM allows for the efficient handling of substantial datasets, facilitating the training of complex models.
The A100’s architecture is designed for versatility, making it suitable for both training and inference, thus catering to a wide range of applications from academia to industry.
It’s an ideal option for teams needing high performance without the elevated costs of the top-tier H100, allowing them to push boundaries in AI development while managing expenses effectively.
L4 (NVIDIA):
The L4 GPU is a cost-effective solution for projects requiring moderate compute power, priced at just $0.000291 per second (or $1.05 per hour). This model shines in scenarios like running Stable Diffusion or executing smaller machine-learning tasks.
With its efficient architecture, the L4 delivers adequate performance for applications that don’t demand the extensive resources of higher-tier GPUs. Ideal for startups, hobbyists, or researchers working on proof-of-concept projects, the L4 allows users to explore AI capabilities without significant financial investment.
Its affordability makes it an attractive option for educational purposes and initial experimentation, providing a solid foundation for those looking to delve into machine learning without overwhelming costs.
Modal’s focus on a smaller set of GPUs allows for streamlined serverless infrastructure, meaning you can scale your workloads up or down in seconds. However, this also means that you have fewer options in terms of lower-tier GPUs, which could be limiting for some users.
Searching for adaptable and scalable GPU cloud services for AI or rendering? CUDO Compute delivers reliable solutions at great prices. Sign up now!
GPU Architecture and Features
RunPod GPU Features
RunPod offers a broader variety of GPUs, allowing you to fine-tune the architecture for your specific workload. The server infrastructure of RunPod is optimized to run both AMD and NVIDIA GPUs, giving users the ability to pick the best tool for the job.
- NVIDIA Ampere and Ada Lovelace Architectures: RunPod offers GPUs like the A100, A5000, A6000, and RTX 3090, all of which are based on NVIDIA’s Ampere architecture. These GPUs deliver excellent performance for both AI inference and training tasks, with a focus on energy efficiency and computational power.
- AMD Instinct MI300X: This GPU is based on AMD’s Instinct architecture, which provides an incredible memory bandwidth and large VRAM, making it well-suited for very large AI models or training tasks.
RunPod also emphasizes serverless functions, enabling users to run tasks without worrying about managing the underlying infrastructure. The platform supports autoscaling, allowing you to scale up to hundreds of GPU instances in real-time.
Modal GPU Features
Modal, while offering fewer GPUs, excels in the serverless GPU space with a highly optimized infrastructure. Modal is built for seamless scaling, allowing workloads to automatically adapt to incoming demand, making it an ideal choice for running AI inference tasks.
- NVIDIA A100 and H100 Architectures: Both the A100 and H100 GPUs offered by Modal are built on NVIDIA’s Ampere architecture, specifically designed for AI workloads. These GPUs are ideal for users looking to run large language models or custom models that require significant computational resources.
- Serverless-first Infrastructure: Modal’s architecture is built around serverless functions, meaning you only pay for what you use. This infrastructure is perfect for users who need to deploy models quickly without worrying about managing hardware or server downtime.
Get instant access to NVIDIA and AMD GPUs on-demand with CUDO Compute—perfect for AI, ML, and HPC projects Sign up now!
Pricing Model Comparison
One of the key differences between RunPod and Modal lies in how they approach pricing. RunPod charges users based on an hourly rate for each GPU instance, while Modal charges per second for GPU usage.
RunPod Pricing Breakdown
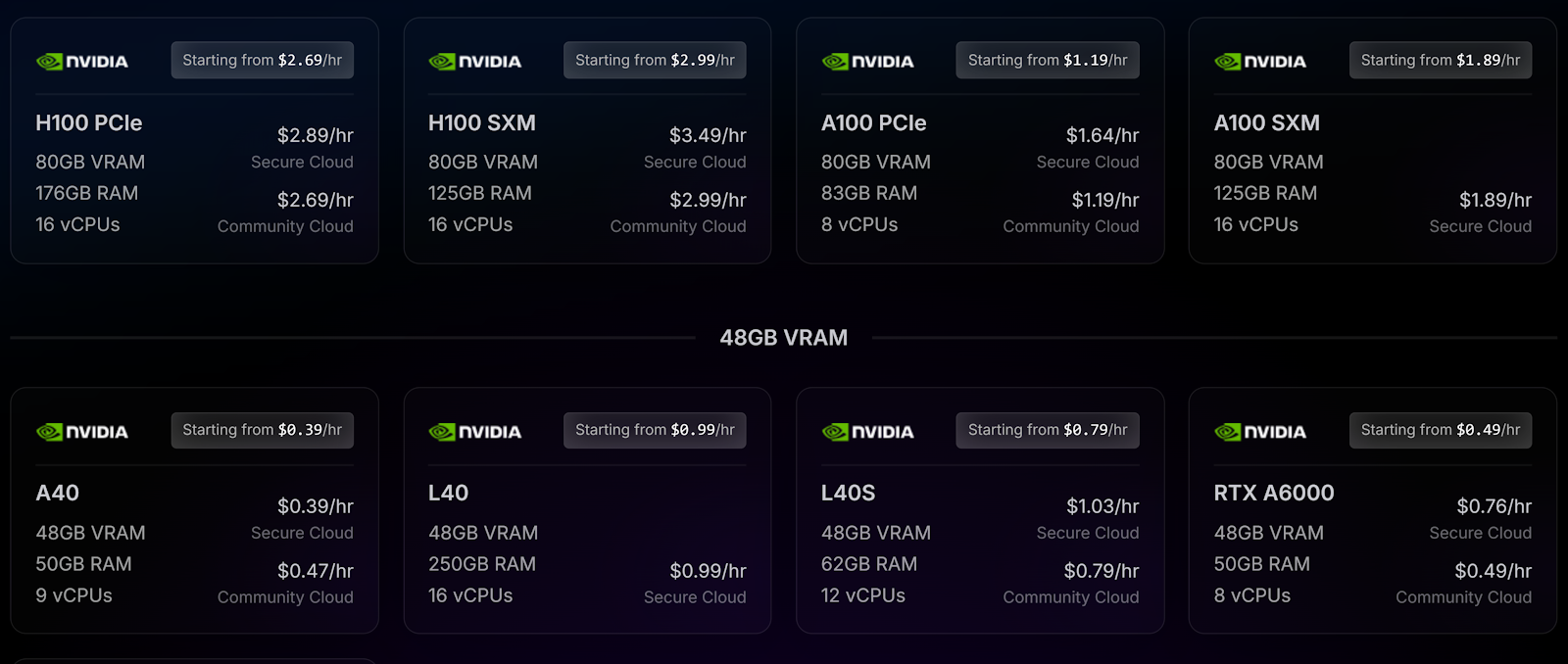
- H100 PCIe: $2.69/hr (Community Cloud), $3.29/hr (Secure Cloud)
- A100 PCIe: $1.19/hr (Community Cloud), $1.69/hr (Secure Cloud)
- RTX A5000: $0.22/hr (Community Cloud), $0.43/hr (Secure Cloud)
RunPod’s pricing model is straightforward. You pay for the GPU instance by the hour, which makes it easier to predict costs for long-running tasks like machine learning training.
Modal Pricing Breakdown
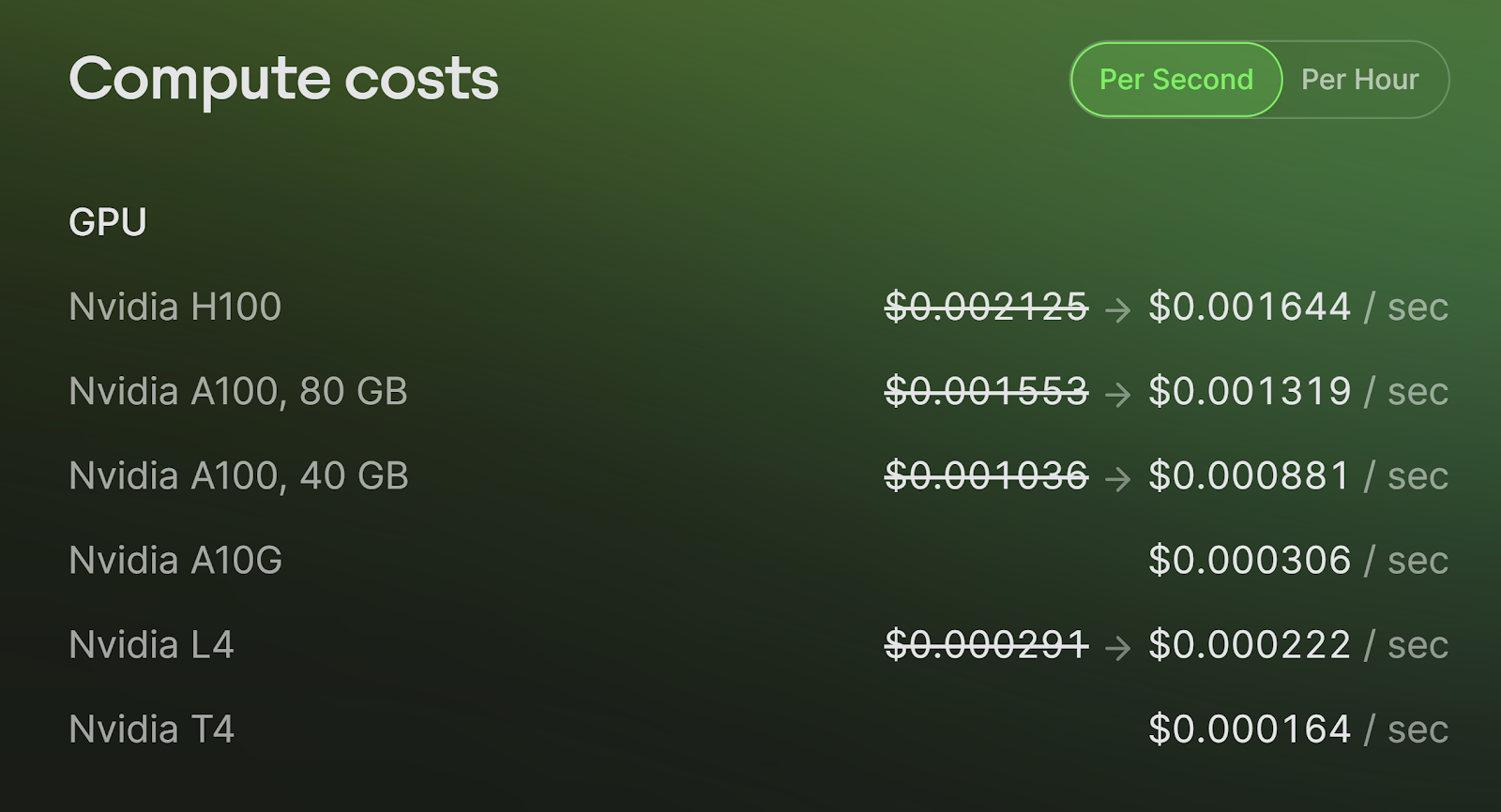
- H100: $0.002125/sec or $7.65/hr
- A100: $0.001553/sec or $5.59/hr
- L4: $0.000291/sec or $1.05/hr
Modal’s pay-per-second pricing allows for granular control over costs, particularly for tasks that don’t require long execution times. This can result in significant savings for users running quick inference tasks or intermittent workloads.
Use Cases and Best Applications
RunPod Use Cases
- AI Model Training: With GPUs like the MI300X and A100, RunPod is well-suited for long-term machine learning training tasks that require large amounts of VRAM and processing power.
- Model Deployment: RunPod’s flexible server infrastructure makes it easy to deploy AI models at scale. With autoscaling, you can manage GPU clusters that grow dynamically with demand, ensuring that you only pay for what you use.
- Machine Learning Inference: For machine learning model inference, RunPod’s serverless infrastructure and fast cold-start times make it a great option for handling large-scale inference workloads, especially for real-time applications.
- Stable Diffusion: With cost-effective GPUs like the RTX 3090, RunPod is an affordable option for running Stable Diffusion models at scale, generating high-quality images quickly and efficiently.
Modal Use Cases
- Machine Learning Inference: Modal’s serverless GPU instances are built for rapid scaling, making it an ideal choice for real-time machine learning inference tasks. It’s particularly effective for applications that require fast response times and can benefit from the H100’s high throughput.
- Custom Models: If you need to deploy custom machine learning models quickly, Modal’s serverless architecture eliminates the need for managing the underlying infrastructure. You can focus purely on the model while Modal handles the autoscaling and deployment.
- Large Language Models: Modal’s high-performance A100 and H100 GPUs are perfectly suited for large language models, making it an excellent option for those working with natural language processing or deep learning applications.
RunPod vs Modal: Which Cloud Provider is Right for You?
Choosing between RunPod and Modal ultimately depends on your specific needs. If you’re looking for serverless GPU providers with a wider variety of GPU models, more cost-effective options, and a highly flexible infrastructure, RunPod may be the better choice for long-term machine learning training or large-scale deployments. On the other hand, if your workloads are focused on short, high-intensity bursts of activity, such as running inference on AI models or custom models in a serverless environment, Modal’s per-second billing and automatic scaling make it an attractive option.
Both providers are strong contenders for the cloud GPUs, but the best choice will depend on your unique workflow and budget.
CUDO Compute offers powerful, cost-effective cloud GPU solutions designed specifically for your AI and ML requirements. Sign up now!