RunPod vs TensorDock: GPU Models, Pricing, and Features

For AI developers and machine learning engineers, access to powerful and affordable GPUs in the cloud is critical. But with options like RunPod and TensorDock on the market, finding the right fit for your workload can be a challenge. RunPod brings a seamless, globally distributed infrastructure that cuts cold-boot times and provides impressive serverless scaling. On the other hand, TensorDock promises budget-friendly, top-tier GPU servers with flexibility for both training and inference tasks.
In this post, we’ll dive into the details of RunPod and TensorDock, comparing GPU models, pricing, and unique features to help you decide which platform best supports your AI goals. Whether you’re scaling deep learning models or building real-time inference pipelines, we’ve got you covered on the pros and cons of each cloud provider.
For a deeper understanding of CUDO Compute, take a look at this informative video:
Table of Contents
GPU Model Selection
Both RunPod and TensorDock offer a wide range of GPU options, giving developers flexibility based on specific performance and budget needs. However, the available models and their configurations differ, affecting everything from compute power to price-per-hour costs.
RunPod GPU Models
RunPod’s offerings focus on a balance of high-end enterprise GPUs suitable for intensive AI tasks and more affordable, consumer-grade GPUs for lighter workloads. Here’s a breakdown of their primary models:
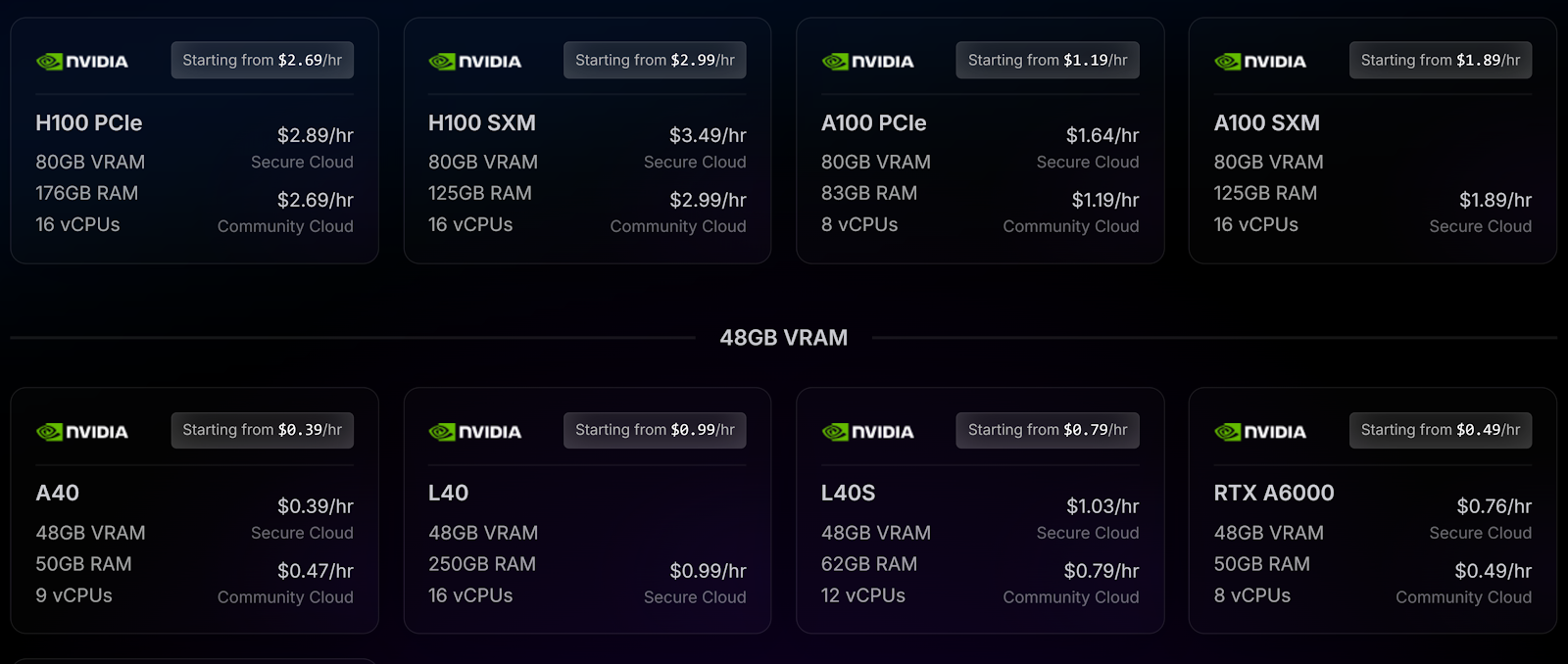
- MI300X (AMD, 192GB VRAM)
Hourly Rate: $3.49
This high-memory GPU is tailored for heavy-duty machine learning and deep learning tasks, particularly those requiring substantial VRAM. While NVIDIA dominates AI/ML workloads, AMD’s MI300X provides competitive performance for both training and inference tasks with a strong price-to-performance ratio. - H100 PCIe (NVIDIA, 80GB VRAM, 188GB RAM, 16 vCPUs)
Hourly Rate: $2.69 on Secure Cloud, $2.99 on Community Cloud
The H100 PCIe is ideal for applications that need extreme parallelism and high-throughput inference or training tasks. With 80GB of VRAM, it handles large-scale deep learning models and massive datasets, particularly suited for advanced AI workloads. - A100 PCIe (NVIDIA, 80GB VRAM, 83GB RAM, 8 vCPUs)
Hourly Rate: $1.19 on Community Cloud, $1.64 on Secure Cloud
Known for versatility, the A100 is suitable for AI training, inference, and high-performance computing applications. This GPU strikes a balance between price and power, making it popular for users needing significant computing resources without the higher cost of an H100. - RTX 4090 (NVIDIA, 24GB VRAM, 26GB RAM, 4 vCPUs)
Hourly Rate: $0.44 on Community Cloud, $0.69 on Secure Cloud
The RTX 4090 provides excellent value for image processing, rendering, and gaming but is also suitable for lighter AI inference tasks. It’s a popular choice for those working on graphics-intensive projects or moderate ML models on a tighter budget.
RunPod also offers lower-cost models like the RTX A6000, A40, and various A-series models (e.g., RTX A4000), which cater to smaller or batch-processing tasks in AI or high-throughput inferencing.
TensorDock GPU Models
TensorDock’s selection spans enterprise-grade GPUs with configurations suited to heavy machine learning tasks and a variety of consumer-grade GPUs for more budget-friendly workloads. Here’s a look at their key models:
- H100 SXM5 (NVIDIA, 80GB VRAM)
Hourly Rate: $2.80
The H100 SXM5 is TensorDock’s top-tier GPU, ideal for workloads requiring high throughput and large model handling, such as large language AI models or real-time inference. This model is especially valuable for tasks requiring uncompromising precision and speed, like image recognition and large neural network training. - A100 SXM4 (NVIDIA, 80GB VRAM)
Hourly Rate: $1.80
The A100 SXM4 offers a more affordable choice for high-performance AI needs, balancing memory capacity and computational power. This GPU is versatile, handling both AI training and inference, making it suitable for general-purpose ML tasks across various industries. - RTX 4090 (NVIDIA, 24GB VRAM)
Hourly Rate: $0.35
TensorDock positions the RTX 4090 as an affordable yet powerful choice for users needing high inferencing performance or graphics rendering. It’s particularly advantageous for small to medium-scale AI workloads and media processing, where high frame rates or fast rendering speeds are critical.
TensorDock’s marketplace approach includes other GPUs like the RTX 3090, RTX A4000, and A6000, providing flexibility across different price points and specifications. This allows users to find a GPU that aligns closely with their workload requirements and budget constraints.
Launch CUDO Compute instances on-demand and benefit from scalable solutions designed to meet all your cloud GPU needs. Sign up now!
Pricing Comparison
RunPod and TensorDock both offer flexible pricing, but their structures have key differences. Here’s how they stack up.
RunPod Pricing Model
RunPod uses a minute-by-minute billing model, which is ideal for developers needing to frequently start and stop tasks without being locked into hourly rates. They also offer both Secure Cloud and Community Cloud pricing tiers:
- Secure Cloud: Higher pricing but with added security and guaranteed resource availability.
- Community Cloud: More affordable, but resources are shared across users and may come with more variable availability.
RunPod also has no ingress/egress fees, which is particularly beneficial for data-intensive applications requiring frequent data transfers.
TensorDock Pricing Model

TensorDock provides a marketplace pricing approach, allowing users to select from GPUs at different rates depending on availability and location. The marketplace concept means that pricing can be highly competitive, particularly for consumer-grade GPUs like the RTX 3090 and RTX 4090, making TensorDock attractive to cost-conscious users who still need strong performance.
TensorDock also allows for a pay-as-you-go model with per-second billing, ideal for users who require short-burst, high-performance tasks. Additionally, discounts are available for long-term subscriptions, which can provide significant savings for users with predictable, ongoing GPU needs.
Choose CUDO Compute for flexible, cost-saving GPU pricing, from hourly rates to multi-month discounts for dedicated resources. Sign up now!
Scalability and Availability
Scalability is a key differentiator in cloud GPU providers, especially for users with fluctuating workloads or those running large-scale training or inference operations.
RunPod Scalability
RunPod offers serverless scaling with instant cold-start times under 250 milliseconds. This rapid scalability is particularly beneficial for ML inference, where real-time performance is crucial. With a network that spans over eight global regions and thousands of GPUs, RunPod provides a reliable foundation for scalable AI and ML operations.
Their autoscaling serverless GPU workers help ensure cost-efficiency since users only pay for resources when they are actively processing data. Additionally, RunPod supports network storage with up to 100 Gbps network throughput, facilitating high-speed data access for large datasets.
TensorDock Scalability
TensorDock operates in a more traditional cloud model, with up to 30,000 GPUs available across 100+ locations. TensorDock’s approach is highly flexible due to its marketplace model, allowing users to scale horizontally across a variety of GPU options based on their project needs.
TensorDock’s tiered availability structure makes it easier to source GPUs quickly, even in high-demand regions. However, TensorDock lacks the instant cold-start scalability seen in RunPod’s serverless platform. Instead, it leans more toward consistent, on-demand scalability through dedicated GPU access.
Storage Options
Storage performance and cost can play a big role in high-volume data applications. Here’s how the two providers approach this need.
RunPod Storage Options
RunPod offers flexible storage with both persistent and temporary options. Pricing varies based on the type of storage, with costs per gigabyte for running pods and idle pods:
- Pod Storage:
Running pods: $0.10/GB/month
Idle pods: $0.20/GB/month - Persistent Network Storage:
$0.07/GB/month for under 1TB
$0.05/GB/month for over 1TB
For users with high storage demands, such as those handling large datasets or running extended training jobs, these prices provide a predictable and affordable option. RunPod also supports network volumes with up to 100TB capacity, scaling to petabyte levels for specialized use cases.
TensorDock Storage Options
TensorDock offers an a la carte pricing approach for storage, allowing users to customize and pay only for what they need. Each block of NVMe SSD storage is billed at a rate of $0.00005 per GB, with the flexibility to add storage as needed without committing to a large volume up-front.
For customers who value granular control over storage costs, TensorDock’s flexible setup is advantageous. This approach is especially suitable for users needing smaller-scale storage or those who prefer to manage storage separately from GPU compute costs.
With CUDO Compute, access the latest high-bandwidth GPUs like the H100 and A100 to power your data-intensive workloads. Sign up now!
Additional Features and Usability
Beyond hardware and pricing, both platforms have unique features designed to improve user experience and efficiency.
RunPod Additional Features
RunPod offers an easy-to-use CLI tool, enabling hot reloading of local changes while developing. This is valuable for developers working on iterative projects, as it reduces the need to continually push container images for each code change. Additionally, RunPod supports both managed and community templates, including preconfigured environments for PyTorch, TensorFlow, and more, streamlining the deployment process.
Their “Bring Your Own Container” model adds flexibility for users needing highly customized environments, as RunPod supports public and private image repositories.
TensorDock Additional Features
TensorDock’s focus on simplicity includes a well-documented API that allows for automated GPU deployment and management. Users benefit from root access and dedicated GPU control, which means compatibility issues with drivers and OS configurations are minimized.
TensorDock’s marketplace also has a vetting system, ensuring only high-quality hardware and reliable hosts are listed. This adds a layer of assurance for users seeking consistent uptime and performance.
RunPod vs TensorDock: The Bottom Line
In short:
- RunPod is better for those prioritizing real-time scalability, serverless architecture, and rapid cold-start times. It’s a solid choice for users focused on ML inference or developers needing seamless environment customization and CLI-based hot-reloading.
- TensorDock is ideal for users seeking flexible, budget-friendly options with high availability across a broad range of GPU models. The marketplace approach can yield cost savings, particularly for projects with more static, predictable requirements or for users looking to leverage lower-cost consumer GPUs.
RunPod excels as a GPU cloud solution for users needing agile, scalable infrastructure with high fault tolerance and serverless capabilities. Its cloud GPUs are well-suited for environments where model training or machine learning inference requires consistent uptime and rapid scalability. With RunPod’s serverless architecture and secure data centers, users can benefit from nearly instant deployment times and efficient resource utilization without incurring the costs associated with idle hardware.
This feature is particularly useful for high-frequency AI model inference tasks, where deep learning frameworks, such as PyTorch or TensorFlow, demand powerful resources for short periods. RunPod also supports containerization and provides extensive Windows support for developers needing a Windows server environment, which can be essential for applications that require specific server hardware configurations or compatibility with Windows-based tools.
On the other hand, TensorDock stands out among GPU providers due to its marketplace model, which allows users to choose from a wide variety of cloud GPUs at highly competitive prices. This setup is particularly appealing for users who prioritize cost savings or have predictable GPU requirements, as it lets them access high-performance server hardware without the overhead associated with traditional dedicated servers. This makes TensorDock a good alternative to other players like Google Cloud Platform, Lambda Labs, Digital Ocean, Azure, and AWS.
TensorDock’s marketplace includes enterprise-grade GPUs, such as the H100 and A100, as well as consumer-grade models like the RTX 3090 and RTX 4090, providing users with flexibility in both price and performance. Additionally, TensorDock includes rest APIs and detailed data center documentation, enabling users to manage resources seamlessly and with full control over their computing power allocation.