Runpod vs Replicate: Cloud GPU Providers for Efficient AI Model Deployment

When it comes to cloud GPU providers, Runpod and Replicate are two strong contenders, each offering unique features tailored to AI and machine learning tasks. Both platforms aim to simplify infrastructure management and help developers focus on what truly matters—running models efficiently. In this Runpod vs Replicate comparison, we dive into the key features, pricing, and scalability options offered by these companies. Whether you’re scaling AI inference with serverless GPUs on Runpod or deploying custom models with ease on Replicate, understanding how these platforms stack up can help you make the right choice for your AI workloads. Let’s break down the strengths and differences to see which service is best suited for your machine learning projects.
Affiliate Disclosure
We prioritize transparency with our readers. If you purchase through our affiliate links, we may earn a commission at no additional cost to you. These commissions enable us to provide independent, high-quality content to our readers. We only recommend products and services that we personally use or have thoroughly researched and believe will add value to our audience.
Table of Contents
Comparing RunPod and Replicate for Cloud GPU Services
When choosing between cloud GPU providers for compute-intensive workloads, RunPod and Replicate are two notable options that offer different strengths. Both cater to AI, machine learning, and other cloud-based computing needs, but each takes a slightly different approach in pricing, infrastructure, and deployment options. This comparison will guide you through their offerings to help you determine which platform aligns with your needs, focusing on their GPU models, architecture, pricing, and features like cloud computer infrastructure, machine learning models, and more.
Looking for adaptable GPU cloud solutions? Check out CUDO Compute for scalable options designed to meet your AI and HPC requirements.
To learn more about CUDO Compute, kindly watch the following video:
Introduction to RunPod and Replicate
Both RunPod and Replicate are built to handle demanding machine learning models, offering secure virtual access to GPU instances for tasks such as AI training, inference, and compute-intensive workloads. They aim to deliver cloud transformation capabilities through a centralized management console while providing competitive pricing and fast, scalable options.
GPU Instances and Compute Power
RunPod’s GPU Options

RunPod excels in offering a wide range of GPU models designed for various workloads. Their infrastructure supports both Nvidia and AMD GPUs, which include the latest models for demanding machine learning tasks. Some key GPUs offered by RunPod include:
Nvidia H100:
Starting at $2.69/hr for the PCIe version and $2.99/hr for SXM models, the Nvidia H100 is engineered for demanding large-scale machine learning and AI tasks. With up to 80GB of VRAM, it excels in processing vast neural networks and complex data pipelines. This model supports multi-GPU setups, making it perfect for distributed computing tasks that require significant parallel processing power. The H100’s architecture ensures faster data transfer rates and enhanced performance for training and inference, delivering cutting-edge acceleration for AI-driven applications and high-performance computing (HPC) environments.
Nvidia A100:
Priced from $1.19/hr, the Nvidia A100 is known as a reliable workhorse for deep learning and AI applications. It offers up to 80GB of VRAM and balances excellent computational performance with cost efficiency, making it widely adopted in cloud computing platforms. Its versatility makes it suitable for both training and inference, supporting mixed-precision workloads, which help speed up processing without sacrificing accuracy. Designed to handle intensive tasks, the A100 is perfect for data scientists working on complex models in deep learning, data analytics, and high-performance cloud computing environments.
Nvidia A40:
Available from $0.39/hr, the Nvidia A40 provides 48GB of VRAM, making it a cost-effective solution for those who need cloud-based virtual machines. This model is ideal for graphics-intensive applications like 3D rendering, simulations, and visualization, as well as for machine learning workloads that don’t require the extreme power of models like the A100 or H100. The A40 is a go-to option for professionals seeking a balance between performance and affordability, offering a flexible solution for data processing, AI development, and virtual desktops in cloud environments.
AMD MI300X:
At $3.99/hr, the AMD MI300X offers an unprecedented 192GB of VRAM, making it one of the best options for handling massive datasets and complex AI workloads. This model is designed for high-demand computing infrastructures that require exceptional memory bandwidth and computational power. The MI300X is particularly suitable for deep learning tasks, large-scale simulations, and high-performance computing environments. Its high VRAM capacity allows for processing larger models and datasets with ease, making it ideal for industries like scientific research, autonomous driving, and advanced AI training tasks.
RunPod is built for versatility, allowing users to bring their own containers or select from 50+ pre-configured templates to quickly deploy environments for PyTorch, TensorFlow, and more. The ability to spin up pods in seconds means developers can start building without waiting for lengthy boot times.
Need high-performance GPUs with clear pricing? Explore CUDO Compute’s offerings to optimize your workloads efficiently.
Replicate’s GPU Options
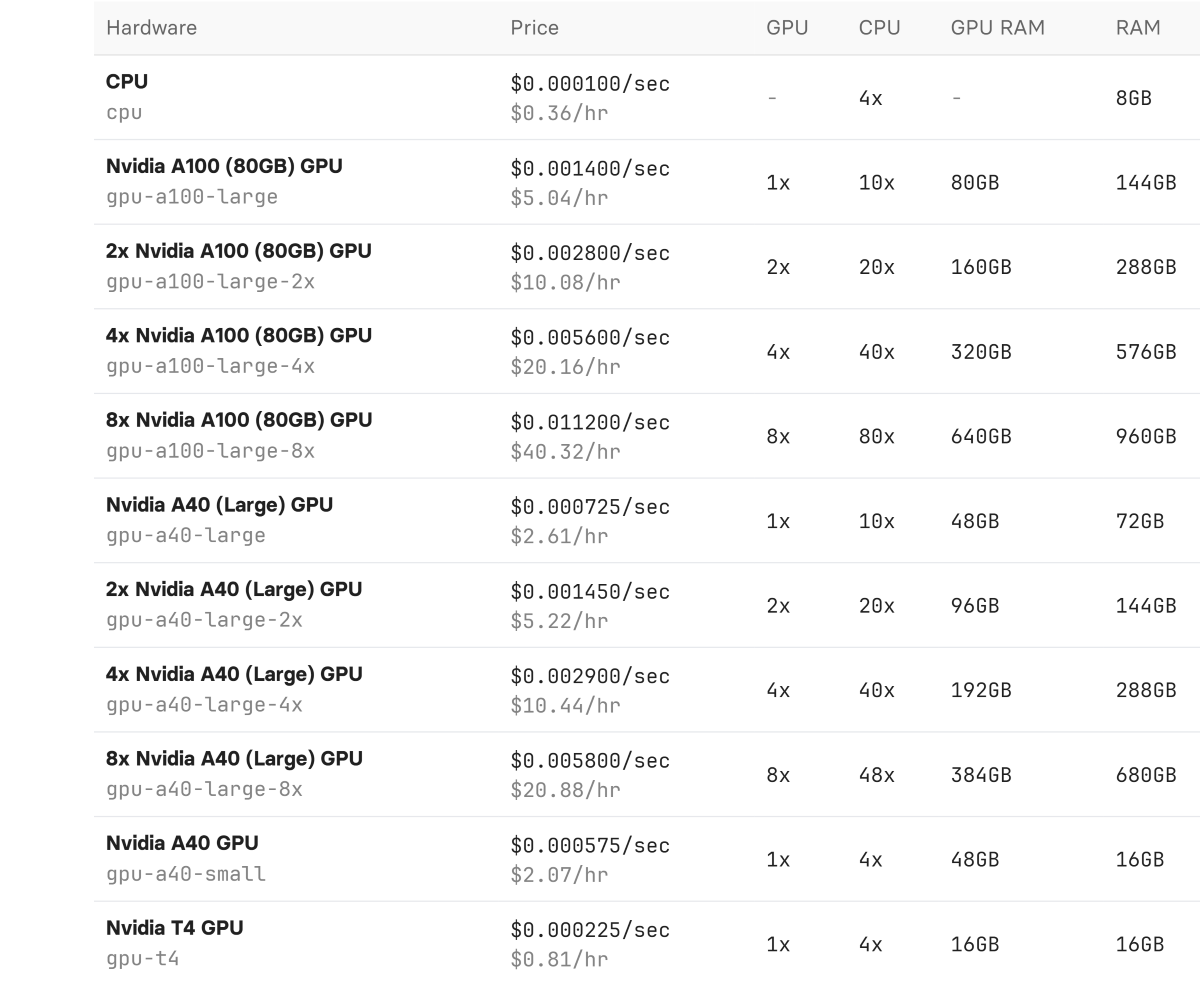
On the other hand, Replicate focuses more on providing a streamlined and efficient pricing model with GPUs billed by the second. Key GPU offerings from Replicate include:
Nvidia A100:
Available for $5.04/hr (or $0.0014 per second), the Nvidia A100 stands out as one of the most powerful GPUs in cloud computing, designed to handle a variety of machine learning workloads. With 80GB of VRAM, it excels at both training and inference tasks, making it a versatile choice for data scientists and AI researchers. Whether you’re building deep learning models, processing large datasets, or running high-performance computing tasks, the A100 provides the computational horsepower needed. Its ability to support mixed-precision workloads also enhances performance without compromising accuracy, making it a top choice for enterprise-level machine learning and AI infrastructure.
Nvidia A40:
At $2.61/hr, the Nvidia A40 is widely used by Replicate for machine learning predictions due to its balance of cost and performance. With 48GB of VRAM, the A40 is a cost-effective option, especially for inference tasks that require substantial memory but not the full power of models like the A100. It’s ideal for use cases such as AI-powered applications, large-scale data analysis, and complex visualizations. The A40 offers a scalable and efficient solution for organizations looking to optimize both cost and performance in cloud environments, particularly for machine learning workflows that demand reliable but moderate computational resources.
Nvidia T4:
Priced at $0.81/hr, the Nvidia T4 is tailored for lighter machine learning workloads, making it a cost-effective solution for models that don’t require massive computational power. It’s well-suited for natural language processing, recommendation systems, and smaller-scale deep learning models. The T4 offers 16GB of VRAM, which, while more modest compared to other high-end GPUs, is enough for a wide variety of applications in the AI and ML space. Its energy efficiency and affordability make it an attractive option for businesses and developers looking to run inference tasks or moderate-scale training in a budget-friendly cloud environment.
While Replicate has fewer GPU models than RunPod, it stands out with its scale-to-zero feature. This means that users only pay when GPUs are actively running, making it an attractive option for developers looking to minimize costs.
Architecture and Deployment
RunPod’s Deployment Flexibility
RunPod emphasizes flexibility and ease of use, offering:
- Seamless deployment: Users can deploy any GPU workload without focusing too much on the infrastructure. With templates ready out of the box, developers can start running machine learning models within seconds.
- Serverless GPU workers: Autoscale from 0 to hundreds of GPUs in seconds. This feature is ideal for cloud-ready foundations and workloads that fluctuate throughout the day, such as AI inference and training tasks.
- Bring your own container: Whether you have a custom image or want to deploy a public or private image repository, RunPod enables easy integration of existing technology, ensuring that users can deploy containers in the cloud computer safely.
- Real-time usage analytics: RunPod provides detailed insights on GPU utilization, failed requests, and execution time, helping to optimize compute-intensive workloads.
Elevate your AI projects with CUDO Compute’s top-tier GPUs. Begin scaling your applications effectively today by visiting here.
Replicate’s Efficient Scaling
Replicate offers a highly scalable infrastructure with the following key features:
- Automatic scaling: Similar to RunPod, Replicate’s infrastructure scales automatically based on demand. However, its pricing model ensures that users are only charged while tasks are running, making it a cost-effective solution for users with unpredictable workloads.
- Public and community models: One of Replicate’s standout features is its extensive library of community-contributed models, which users can run or modify without building from scratch. This can save considerable time in development for smaller teams or startups.
- Simple API integration: Replicate simplifies the deployment of machine learning models by allowing users to run models via an API. This is particularly beneficial for developers looking to integrate cloud-based virtual machines into their existing workflows without having to handle the complexity of infrastructure management.
Pricing Comparison
| GPU Model | RunPod Pricing | Replicate Pricing |
| Nvidia H100 PCIe | $2.69/hr (80GB VRAM, 176GB RAM) | Not available |
| Nvidia A100 PCIe | $1.19/hr or $0.00076 per second | $5.04/hr or $0.0014 per second |
| Nvidia A40 | $0.39/hr (Moderate VRAM workloads) | $2.61/hr (Used for most community models) |
| Nvidia T4 | Not available | $0.81/hr (For lighter workloads) |
| AMD MI300X | $3.99/hr (192GB VRAM, Compute-heavy tasks) | Not available |
RunPod’s Pricing Model
RunPod’s pricing is based on the GPU model, with options for both secure cloud and community cloud access. It also offers by-the-minute billing, ensuring that users only pay for the time they use. Notable pricing details include:
- Nvidia H100 PCIe: Starts at $2.69/hr, offering 80GB VRAM and 176GB RAM.
- Nvidia A100 PCIe: Priced at $1.19/hr, making it a cost-effective option for deep learning models.
- Nvidia A40: Available from $0.39/hr, making it a low-cost option for workloads with moderate VRAM requirements.
- AMD MI300X: At $3.99/hr, this GPU offers massive VRAM (192GB) and is designed for compute-heavy tasks.
RunPod’s serverless pricing also stands out, especially for AI inference tasks. For example, the A100 is priced at $0.00076 per second, which allows users to run small inference tasks very cost-effectively. Additionally, flex workers provide further cost savings through queue delay optimization.
Replicate’s Pricing Model
Replicate’s pricing model is simple, charging per second for both GPU and CPU instances:
- Nvidia A100: Priced at $5.04/hr or $0.0014 per second, Replicate is ideal for users who need powerful GPUs for short bursts of activity.
- Nvidia A40: Available at $2.61/hr, this GPU is used for most of the community models.
- Nvidia T4: For lighter workloads, the T4 is available at $0.81/hr.
One of the advantages of Replicate is its ability to scale to zero, meaning if your GPU is not running, you’re not paying. This is especially useful for developers who need to occasionally spin up a GPU for testing but don’t want to commit to hourly charges.
Looking for budget-friendly GPUs? Explore CUDO Compute’s competitive offerings designed for demanding tasks.
Centralized Management and Control
Both RunPod and Replicate offer strong centralized management options, although their approaches differ slightly.
RunPod’s Management Console
RunPod offers a centralized management console that allows users to deploy and manage cloud-based virtual machines and GPU instances. Users can monitor the health and performance of their GPUs, track costs, and scale resources up or down in real-time. Additionally, RunPod supports multi-region deployment with 99.99% uptime, making it a reliable option for mission-critical tasks.
Replicate’s Simple API Integration
Replicate’s focus is on simplicity and API-based workflows. Developers can integrate their models into existing applications or cloud provider infrastructures without worrying about complex configuration or management tasks. This is ideal for teams that need a simple, plug-and-play solution.
Storage and Data Management
RunPod’s Network Storage
RunPod offers flexible, NVMe-backed network storage with up to 100Gbps throughput. Users can customize their pod volumes and access additional persistent storage, with pricing starting at $0.10/GB/month. This allows for easy management of large datasets, essential for AI and machine learning workflows.
Replicate’s Public Model Repository
While Replicate doesn’t offer explicit storage options like RunPod, it provides access to thousands of community-contributed models. Users can run models without needing to store massive datasets locally, which can save storage costs and complexity. However, if users need to train large datasets, they’ll likely need to integrate external storage solutions.
Unlock your computing potential with CUDO Compute. Discover more about their advanced GPU services here.
Security and Compliance
Both platforms prioritize security, with features meticulously designed to ensure cloud computing safety and secure virtual access.
RunPod:
This platform is built on enterprise-grade GPUs, adhering to world-class compliance and security standards. RunPod supports secure cloud deployments with robust measures in place to protect data and infrastructure.
One key feature is its support for private container images, allowing users to bring their own pre-configured environments. This ensures that sensitive data remains protected throughout deployment and minimizes the risk of exposure to unauthorized access.
Additionally, RunPod’s infrastructure is designed to handle complex security requirements, making it suitable for organizations with stringent data protection needs.
Replicate:
While Replicate may not offer the same enterprise-grade security features as RunPod, it still maintains a secure environment for running machine learning models.
The platform’s ability to scale to zero is a notable security benefit, as it ensures that GPU instances are only active when required, thereby reducing potential attack vectors. By scaling resources based on demand, Replicate helps minimize the risk of vulnerabilities associated with idle or unused instances.
Furthermore, Replicate implements strong access controls and encryption protocols to safeguard user data, providing a secure foundation for developing and deploying machine learning applications.
Use Cases and Recommendations
When to Choose RunPod
RunPod is the better choice for users who need:
- A wide range of GPU instances, including Nvidia and AMD options.
- Flexibility in deployment with pre-configured templates or custom containers.
- Serverless autoscaling for real-time demand and 99.99% uptime.
- Access to high-performance storage and real-time usage analytics.
When to Choose Replicate
Replicate is a strong option for users who:
- Want a pay-per-second pricing model, ideal for short bursts of GPU usage.
- Require simple API integration for running models without worrying about complex infrastructure.
- Appreciate the ability to scale to zero, minimizing costs when GPUs aren’t in use.
- Prefer using community-contributed models for quick deployment of machine learning models.
Runpod vs Replicate: Conclusion
Both RunPod and Replicate offer robust GPU cloud solutions tailored to different needs.
RunPod stands out with its full-featured licensing model, versatile range of GPU options, and integration with other Google Cloud services, making it a strong choice for those needing a comprehensive computing infrastructure.
Its pricing flexibility supports public cloud deployments and provides a solid cloud-ready foundation.
On the other hand, Replicate’s pay-per-second pricing and API-driven approach are ideal for users seeking simplicity and cost-efficiency for shorter tasks.
While Replicate excels in its straightforward model and ability to scale to zero, RunPod’s rich features and broader integration make it the go-to for extensive and varied GPU needs.
Elevate your computing capabilities with CUDO Compute. Explore their cutting-edge GPU services here.