Baseten vs Replicate: GPUs, Pricing and Performance Breakdown

Cloud GPUs are changing the game for AI developers and businesses alike. They offer the power needed to train, fine-tune, and deploy machine learning models without the headaches of maintaining expensive hardware. Whether you’re scaling up a chatbot, fine-tuning an image generator, or deploying a custom model, having the right platform can make or break your project.
Two names that stand out are Baseten and Replicate. Both promise scalable, fast, and developer-friendly solutions. But when you dig deeper—looking at GPU models, performance, and pricing—differences emerge.
This post unpacks everything you need to know about these two platforms. We’ll look at the GPUs they offer, how they handle scalability, and what their pricing models really mean for your budget. Ready to figure out which one might work for you?
Table of Contents
Baseten vs Replicate: Overview
| Feature | Baseten | Replicate |
| Pricing Model | Pay-as-you-go, billed by the minute. | Pay-as-you-go, billed by the second. |
| Supported GPUs | T4, L4, A10G, A100, H100 (MIG options available). | T4, A40 (small/large), A100 (80GB, with multi-GPU options). |
| Hardware Pricing | Starts at $0.01052/min for T4, up to $0.1664/min for H100. | Starts at $0.000225/sec for T4 ($0.81/hour), up to $0.0112/sec for 8x A100s ($40.32/hour). |
| Developer Tools | Truss: Open-source packaging, instant deployment, and observability tools. | Cog: Open-source tool for model packaging and API deployment. |
| Autoscaling | Automatic horizontal scaling based on traffic, with near-zero cold start times. | Automatic scaling to zero when idle; scales up automatically for high demand. |
| Model Library | OpenAI Whisper, SDXL, and customizable model options. | Thousands of open-source models (e.g., Stable Diffusion, Mistral, Llama). |
| Security | HIPAA-compliant, SOC 2 Type II certified, offers single tenancy for enhanced isolation. | No specific certifications mentioned; private models available with additional cost considerations. |
| Ease of Deployment | Command-line interface (pip install truss and push). | Automatic API generation with seamless deployment. |
| Inference Performance | Optimized for low-latency tasks (e.g., chatbots), supports up to 1,500 tokens per second. | Performance depends on GPU model; public models list typical run times and costs. |
| Customization | Self-hosting and deployment on private cloud supported. | Focuses on running community-contributed and private models in a shared cloud environment. |
| Best for | Enterprises needing enterprise-grade compliance, fast scaling, and extensive observability. | Developers seeking flexible, community-driven options for model deployment and experimentation. |
Affiliate Disclosure
We are committed to being transparent with our audience. When you purchase via our affiliate links, we may receive a commission at no extra cost to you. These commissions support our ability to deliver independent and high-quality content. We only endorse products and services that we have personally used or carefully researched, ensuring they provide real value to our readers.
GPU Models and Pricing
Baseten GPU Offerings
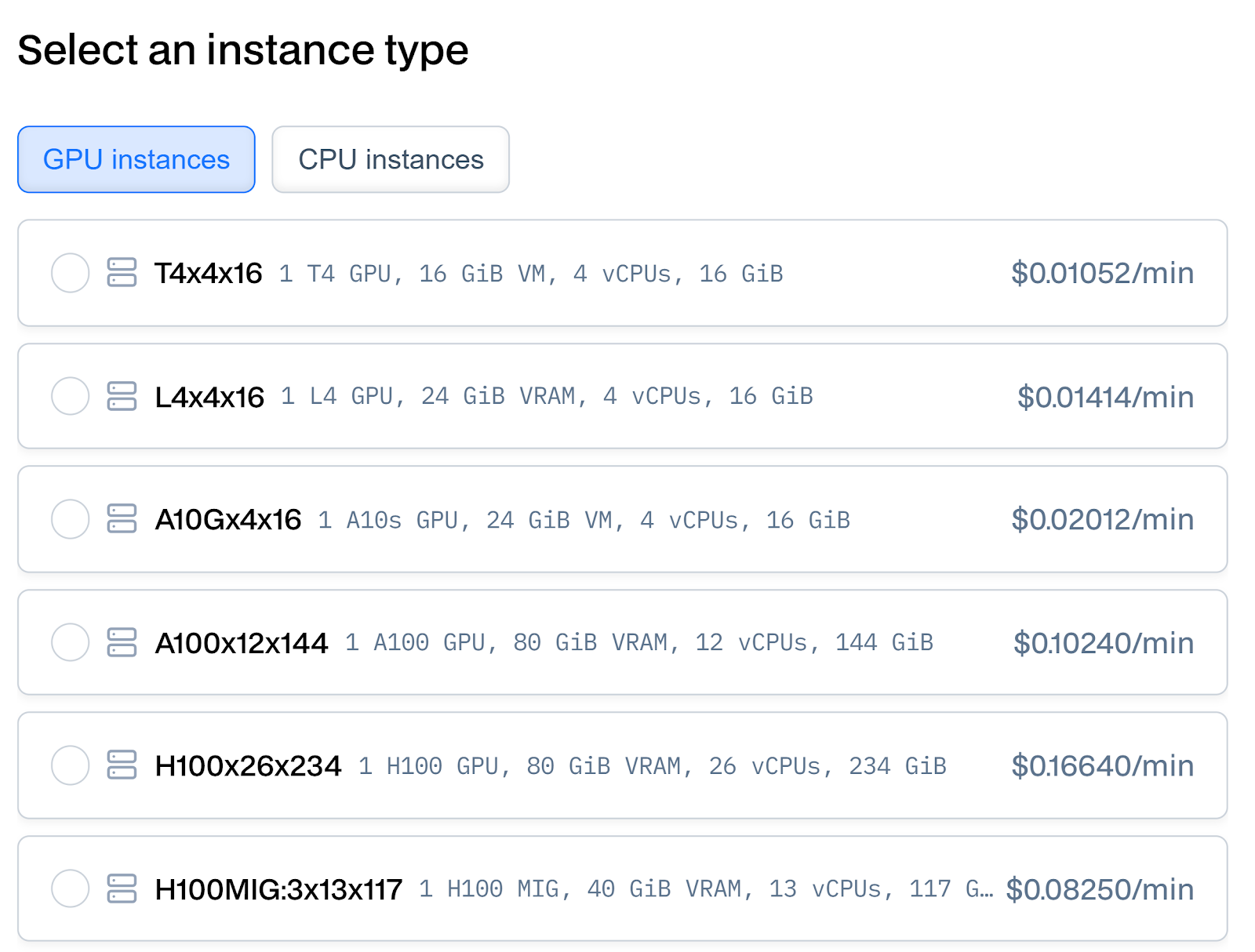
Baseten provides a variety of GPU options designed for diverse workloads:
- Nvidia T4 GPU
- Specs: 16 GB VRAM, 4 vCPUs, 16 GB RAM.
- Pricing: $0.01052/min ($0.6312/hr).
- Use Cases: Entry-level GPU ideal for lightweight machine learning tasks, inferencing, and small-scale deployment.
- Nvidia L4 GPU
- Specs: 24 GB VRAM, 4 vCPUs, 16 GB RAM.
- Pricing: $0.01414/min ($0.8484/hr).
- Use Cases: Suitable for AI inferencing, video processing, and graphics-intensive tasks.
- Nvidia A10G GPU
- Specs: 24 GB VRAM, 4 vCPUs, 16 GB RAM.
- Pricing: $0.02012/min ($1.2072/hr).
- Use Cases: Great for training medium-sized AI models and inferencing at scale.
- Nvidia A100 GPU
- Specs: 80 GB VRAM, 12 vCPUs, 144 GB RAM.
- Pricing: $0.10240/min ($6.144/hr).
- Use Cases: Ideal for high-performance computing, deep learning model training, and large-scale inferencing.
- Nvidia H100 GPU
- Specs: 80 GB VRAM, 26 vCPUs, 234 GB RAM.
- Pricing: $0.16640/min ($9.984/hr).
- Use Cases: Exceptional for cutting-edge AI applications requiring the highest computational power, such as generative AI and large-scale language models.
- Nvidia H100 MIG (Multi-Instance GPU)
- Specs: 40 GB VRAM, 13 vCPUs, 117 GB RAM.
- Pricing: $0.08250/min ($4.95/hr).
- Use Cases: Perfect for multi-tenancy and cost-efficient inferencing in shared environments.
Replicate GPU Offerings

Replicate offers flexible GPU pricing tailored to workloads and scales. The following are the most popular configurations:
- Nvidia T4 GPU
- Specs: 16 GB VRAM, 4x CPUs, 16 GB RAM.
- Pricing: $0.000225/sec ($0.81/hr).
- Use Cases: Entry-level GPU optimized for lightweight inferencing and low-cost workloads.
- Nvidia A40 GPU (Small)
- Specs: 48 GB VRAM, 4x CPUs, 16 GB RAM.
- Pricing: $0.000575/sec ($2.07/hr).
- Use Cases: Versatile choice for moderate machine learning training and inferencing tasks.
- Nvidia A40 GPU (Large)
- Specs: 48 GB VRAM, 10x CPUs, 72 GB RAM.
- Pricing: $0.000725/sec ($2.61/hr).
- Use Cases: Excellent for heavier workloads like video rendering and complex machine learning tasks.
- Nvidia A100 GPU (80 GB)
- Specs: 80 GB VRAM, 10x CPUs, 144 GB RAM.
- Pricing: $0.0014/sec ($5.04/hr).
- Use Cases: Tailored for advanced AI applications requiring high memory and computational capacity.
- Multi-GPU Configurations (e.g., 2x A100, 4x A100, 8x A100)
- Pricing: Ranges from $0.0028/sec ($10.08/hr) for 2x A100 to $0.0112/sec ($40.32/hr) for 8x A100.
- Use Cases: Perfect for massive parallel workloads, distributed training, and generative AI models.
Launch AI workloads instantly on performant NVIDIA and AMD GPUs, designed for deep learning, rendering, and scalable enterprise applications. Sign up now!
Performance and Scalability
Baseten
- Inference Speed: Up to 1,500 tokens per second with latency under 100ms, making it ideal for real-time applications.
- Autoscaling: Automatically scales from zero to thousands of replicas based on traffic, ensuring consistent performance without overpaying for unused resources.
- Cold Start Optimization: Models start in under 2 seconds, thanks to optimized pipelines.
- Infrastructure: Supports both self-hosted deployments and deployments within your own cloud.
- Supported Frameworks: PyTorch, TensorFlow, TensorRT, and Triton.
Replicate
- Scalability: Automatically scales down to zero during inactivity, reducing idle costs.
- Flexibility: Offers public and private model hosting, with APIs generated for custom models.
- Multi-GPU Efficiency: Handles distributed training with multi-GPU configurations efficiently.
- Model Library: Thousands of open-source models available, simplifying the setup for new users.
- Cold Start: Performance depends on workload and hardware but scales quickly under demand.
Cost Management
Baseten
- Charges by the minute, ensuring precise billing.
- Provides detailed cost tracking and optimization recommendations.
- Includes resource and log management tools for enhanced cost visibility.
Replicate
- Charges by the second, making it suitable for highly variable workloads.
- Scales to zero when not in use, eliminating idle costs.
- Offers transparent per-token pricing for language models.
Use Case Comparisons
Both Baseten and Replicate cater to diverse workloads within the serverless GPU space, but their strengths shine in different areas. Replicate is an excellent choice for lightweight and cost-sensitive tasks due to its affordable pricing and second-based billing. On the other hand, Baseten excels in handling medium to large-scale workloads, thanks to its balanced pricing, enterprise-grade tools, and support for advanced GPUs like the H100.
When choosing between serverless GPU providers, it’s crucial to assess your specific workload, whether it involves data processing, model inference, or training ML models. Both cloud providers offer robust solutions, but their unique features make them better suited to certain scenarios.
The serverless GPU space has grown significantly, offering data scientists, ML engineers, and businesses flexible options for handling diverse workloads. Both Baseten and Replicate provide robust serverless GPUs, but the choice between them depends heavily on the use case. Here’s an expanded comparison of their strengths across different scenarios.
Lightweight Tasks: Replicate Shines in Cost-Effectiveness
Winner: Replicate
Why: Replicate’s T4 GPU instances offer the lowest hourly cost, coupled with second-based billing, making it ideal for sporadic or small-scale tasks.
Replicate’s Advantages:
- Second-Based Billing: By charging down to the second, Replicate ensures users only pay for the exact compute time they need, minimizing expenses for intermittent tasks.
- Affordable GPU Resources: The T4 instance is priced at $0.000225 per second (around $0.81/hour). This makes it perfect for workloads like inferencing with pre-trained models or lightweight data processing.
Best Use Cases:
- Model inference for popular models like Stable Diffusion or Mistral, where high performance isn’t critical.
- Prototyping and testing ML workflows with minimal resource consumption.
- Running simple data transformations or periodic ML models for analytics.
While Baseten also offers T4 GPUs at $0.01052 per minute, Replicate’s second-based billing provides finer cost control, making it more suitable for lightweight, sporadic tasks.
Medium-Scale Machine Learning: Baseten Offers the Sweet Spot
Winner: Baseten
Why: The A10G GPU from Baseten provides an excellent balance of performance and cost for sustained workloads, priced at $1.2072/hour.
Baseten’s Advantages:
- Optimized GPU Resources: The A10G features 24GB of memory and strong compute power, catering to tasks that demand steady performance without breaking the bank.
- Serverless Platform for ML Models: Baseten’s seamless deployment tools, including Truss, make it easier for data scientists to deploy and manage medium-scale workloads on a serverless platform.
- Scalability: Baseten supports horizontal scaling for models, ensuring reliable performance as demand increases.
Best Use Cases:
- Training ML models on medium datasets.
- Running production-grade model inference pipelines for customer-facing applications.
- Processing real-time data feeds with moderate computational requirements.
Compared to Replicate, Baseten stands out with its user-friendly scaling and tools tailored for managing active workloads.
Large-Scale AI Training: A Draw Between the Providers
Winner: Tie
Why: Both Baseten and Replicate offer A100 GPUs at competitive rates, along with strong support for scaling large workloads.
Shared Advantages:
- High-End GPU Resources: The A100, with 80GB of memory, is well-suited for large-scale training of complex ML models and data processing tasks.
- Scalability: Both platforms allow users to scale up with multiple GPUs (e.g., 2x or 4x A100 configurations on Replicate) to handle extensive workloads.
- Competitive Pricing:
- Baseten’s A100 instance is priced at $0.1024 per minute (approximately $6.14/hour).
- Replicate’s A100 starts at $0.0014 per second (around $5.04/hour), with multi-GPU setups available for more demanding tasks.
Best Use Cases:
- Training large ML models or fine-tuning pre-trained models like Llama or Mistral on extensive datasets.
- Computationally intensive data processing tasks require high throughput.
- Applications in industries like genomics, autonomous systems, and advanced NLP.
The choice here largely depends on the user’s workflow preferences. Replicate’s second-based billing provides better cost efficiency for intermittent training, while Baseten’s serverless platform excels in providing enterprise-ready tools and compliance for continuous workloads.
High-Performance Generative AI: Baseten Leads with H100 GPUs
Winner: Baseten
Why: Baseten’s H100 GPUs, combined with Multi-Instance GPU (MIG) support, deliver unmatched performance for generative AI and large-model training.
Baseten’s Advantages:
- Advanced GPU Hardware: The H100 GPU offers 80GB of memory and significant improvements in compute power compared to the A100. This makes it perfect for demanding generative AI applications.
- MIG Support: Baseten’s ability to partition the H100 GPU into multiple isolated instances ensures optimized usage and cost-effectiveness for diverse workloads.
- Enterprise-Ready Serverless GPUs: With compliance certifications like SOC 2 and HIPAA, Baseten provides the security and reliability needed for critical business applications.
Best Use Cases:
- High-resolution image generation, such as running SDXL or other generative AI popular models.
- Training or fine-tuning large transformer-based models for NLP, like GPT-style architectures.
- Large-scale data processing for simulations or predictive modeling.
While Replicate doesn’t currently offer H100 GPUs, its A100 multi-GPU configurations can still handle many generative AI workloads. However, Baseten’s focus on cutting-edge hardware makes it the go-to choice for enterprises and data scientists pushing the limits of AI.
Deploy pre-trained models and machine learning pipelines on cutting-edge GPUs like the H100, offering unmatched memory bandwidth. Sign up now!
Developer Tools and Features
Baseten
- Truss: Open-source model packaging tool for deployment in any environment.
- Observability Tools: Tracks metrics like inference counts, response times, and GPU uptime.
- Single Tenancy: Enhances security for enterprise clients.
Replicate
- Cog: Open-source tool for packaging and deploying machine learning models.
- Public Model Library: Thousands of ready-to-use models.
- API Generation: Automatically creates endpoints for hosted models.
Final Thoughts
Baseten and Replicate are standout players in the serverless GPU market, each catering to different user needs and priorities. Your choice ultimately depends on what matters most for your projects.
Baseten is the go-to platform for businesses seeking enterprise-level security and high performance. With compliance certifications like HIPAA and SOC 2 Type II, it’s designed to meet stringent regulatory requirements, making it ideal for industries like healthcare and finance. Baseten’s infrastructure excels in low-latency scenarios, which are critical for real-time applications such as chatbots, virtual assistants, and interactive AI tools. The inclusion of advanced hardware like the H100 GPU and seamless autoscaling ensures it can handle demanding tasks like generative AI and large-scale model training efficiently.
On the other hand, Replicate shines with its cost-efficient and flexible offerings. The second-based billing system ensures you only pay for what you use, making it perfect for sporadic or small-scale workloads. Replicate’s rich library of public models simplifies workflows for developers and data scientists, allowing them to experiment with pre-trained models without additional setups. For lightweight and mid-sized tasks, Replicate provides great value, especially with affordable options like the T4 and A40 GPUs.
Both platforms excel in their own right, but understanding your project’s scope, budget, and performance needs will help you choose the best fit for your use case.