Modal vs AWS EC2 GPU Comparison

Cloud GPUs have changed the game for developers and businesses running AI, ML, and high-performance computing tasks. They offer the flexibility to scale resources up or down and the power to handle intense workloads without the hassle of managing physical hardware.
AWS is an established GPU provider like Google Cloud whereas Modal is a relatively new player in this space. Both promise cutting-edge performance, seamless scaling, and developer-friendly features. But which one delivers better value? We’re here to break it down for you—from GPU models to pricing and everything in between. By the end of this post, you’ll know how these two stack up and which might suit your needs best.
Table of Contents
GPU Model Offerings
AWS EC2 GPUs
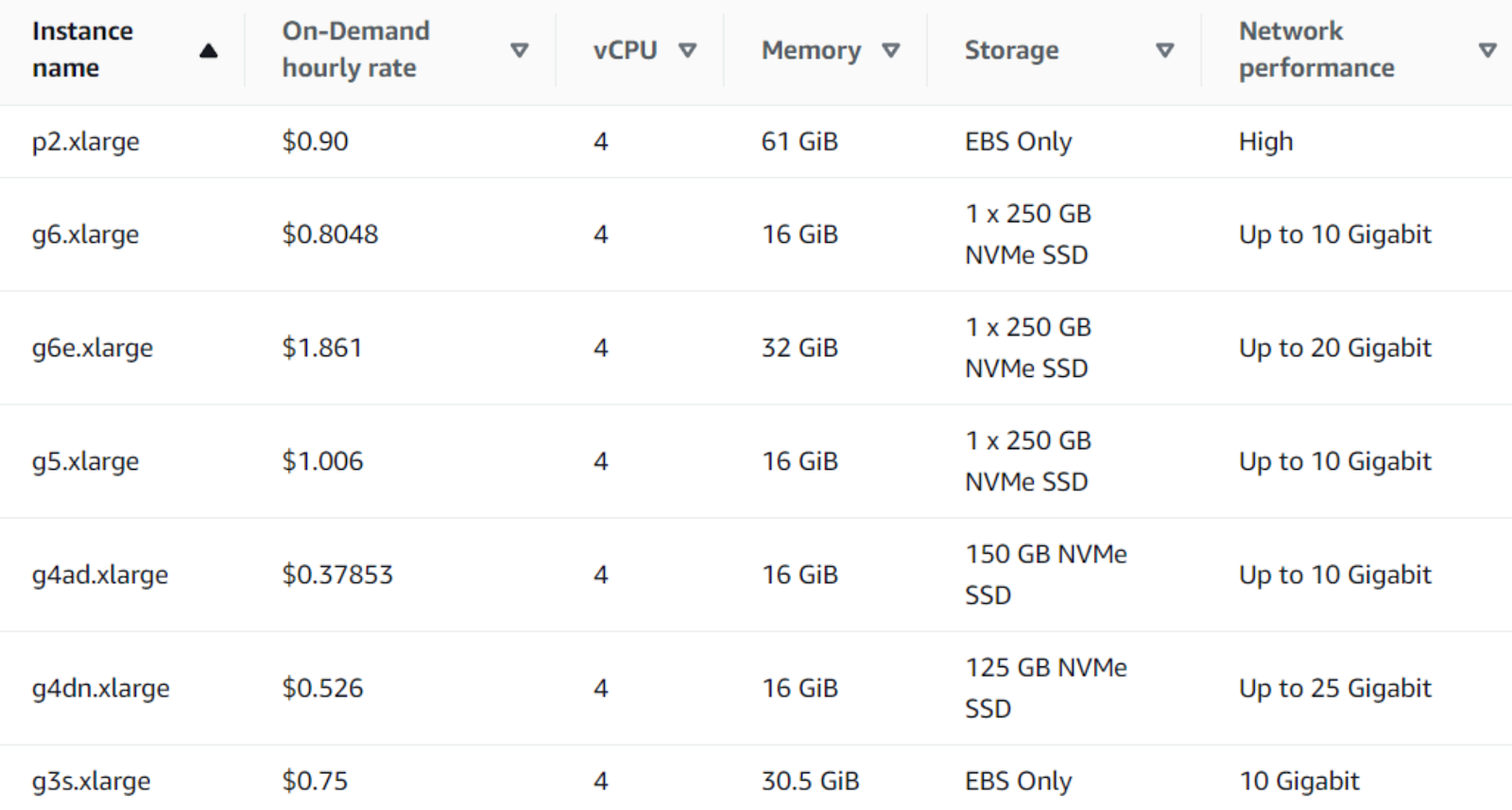
AWS EC2 provides a diverse range of GPU instances tailored for various workloads, from graphics rendering and video encoding to AI model training and inference. AWS GPU offerings include G3, G4, G5, G6, and P2 instances. Each instance type is optimized for specific use cases.
- G3 Instances (NVIDIA Tesla M60):
- Features:
- Up to 4 NVIDIA Tesla M60 GPUs per instance.
- 2,048 parallel processing cores per GPU.
- 8 GiB of GPU memory per GPU.
- Use Cases:
- 3D rendering, video encoding, and application streaming.
- Pricing:
- Starts at $0.75/hour for the g3s.xlarge instance (Linux on-demand).
- Features:
- G4 Instances:
- G4dn (NVIDIA T4 GPUs):
- Up to 8 NVIDIA T4 GPUs per instance.
- Optimized for machine learning inference and small-scale training.
- Pricing starts at $0.526/hour for the g4dn.xlarge.
- G4ad (AMD Radeon Pro V520 GPUs):
- Up to 4 GPUs per instance.
- Offers 45% better price performance for graphics-intensive applications compared to G4dn.
- Pricing starts at $0.379/hour for the g4ad.xlarge.
- G4dn (NVIDIA T4 GPUs):
- G5 Instances (NVIDIA A10G GPUs):
- Features:
- Up to 8 GPUs per instance.
- High performance for graphics-intensive applications and machine learning inference.
- Local NVMe storage.
- Pricing:
- Starts at $1.006/hour for the g5.xlarge instance.
- Features:
- G6 Instances (NVIDIA L4 GPUs):
- Features:
- Up to 8 GPUs per instance.
- High-performance GPU-based instances for deep learning inference.
- Pricing:
- Starts at $0.805/hour for the g6.xlarge.
- Features:
- P2 Instances (NVIDIA K80 GPUs):
- Features:
- Up to 16 GPUs per instance.
- Combined 192 GiB of GPU memory.
- Use Cases:
- Deep learning and high-performance computing.
- Pricing:
- Starts at $0.90/hour for the p2.xlarge instance.
- Features:
Modal GPUs
Modal focuses on high-performance AI and ML workloads, emphasizing serverless cloud functionality. Modal’s GPU options are streamlined and geared towards scalability and flexibility.
- NVIDIA H100:
- Features:
- State-of-the-art performance for AI model training and inference.
- Optimized for large-scale AI workloads.
- Pricing:
- $4.56/hour.
- Features:
- NVIDIA A100 (80 GB):
- Features:
- Suitable for AI and data-heavy applications.
- Faster memory access and parallel processing capabilities.
- Pricing:
- $3.40/hour.
- Features:
- NVIDIA A100 (40 GB):
- Features:
- A cost-effective alternative to the 80 GB variant with similar compute capabilities.
- Pricing:
- $2.78/hour.
- Features:
- NVIDIA A10G:
- Features:
- Designed for AI inference and small-scale training.
- Pricing:
- $1.10/hour.
- Features:
- NVIDIA L4:
- Features:
- Optimized for inference and video processing workloads.
- Pricing:
- $0.80/hour.
- Features:
- NVIDIA T4:
- Features:
- Suitable for entry-level AI workloads and graphics rendering.
- Pricing:
- $0.59/hour.
- Features:
With CUDO Compute, deploy cutting-edge GPUs like H200 and L40S starting at just $1.41 per hour! Sign up now!
Features and Performance Comparison
| Feature | AWS EC2 | Modal |
| Pricing Model | On-demand, Reserved Instances, Spot Instances | Pay-as-you-go (pay-per-second) |
| Ease of Use | Requires setup and configuration | Serverless, minimal management |
| Autoscaling | Moderate (manual adjustments often required) | Rapid and automatic |
| GPU Models | Wide variety (T4, A10G, A100, etc.) | Streamlined (H100, A100, T4, etc.) |
| Integration | Seamless with AWS ecosystem | Python-centric, developer-friendly |
| Workload Fit | Sustained, long-term projects | Bursty, unpredictable workloads |
| Security | Compliance with industry standards | SOC 2, HIPAA compliance |
AWS EC2:
AWS EC2 provides unparalleled flexibility with its wide range of GPU models, catering to both entry-level and high-performance needs. From NVIDIA T4 GPUs in G4 instances for lightweight inference tasks to cutting-edge NVIDIA A100 GPUs in P4d instances for deep learning, EC2 supports an extensive variety of workloads. Reserved Instances and Spot Instances offer cost-saving options, enabling users to align costs with their usage patterns. Reserved Instances are ideal for long-term, predictable workloads, while Spot Instances allow users to take advantage of unused capacity at significantly reduced rates.
Scalability is another strength of AWS EC2. Users can deploy resources across multiple regions, ensuring low latency and compliance with regional regulations. This multi-region support makes AWS EC2 suitable for global enterprises that require reliable and consistent performance. Additionally, AWS’s advanced networking capabilities, such as Elastic Fabric Adapter (EFA), enhance scalability for high-throughput workloads, including distributed machine learning and HPC tasks.
Modal:
Modal prioritizes simplicity and efficiency with its serverless architecture. Unlike AWS EC2, Modal does not require reserved instances or intricate setup processes. Users benefit from pay-per-second pricing, ensuring they only pay for the resources they actively use. This approach is particularly advantageous for bursty workloads or short-term projects where idle resources would otherwise incur unnecessary costs.
Modal’s rapid autoscaling capabilities set it apart, allowing developers to scale resources up or down in seconds. This feature is especially useful for AI and ML developers who need to train machine learning models or handle dynamic workloads. GPUs like NVIDIA H100 and A100 can be provisioned instantly, enabling seamless transitions from development to deployment without infrastructure bottlenecks. Modal’s serverless nature eliminates the complexity of managing infrastructure, making it an excellent choice for teams focused on agility and innovation.
Winner: Modal for rapid autoscaling and cost efficiency for bursty workloads; AWS for broader regional support and pricing models.
Pricing
| GPU Model | AWS EC2 Pricing | Modal Pricing |
| NVIDIA T4 | Starts at $0.526/hour (G4dn.xlarge) | $0.59/hour |
| NVIDIA A10G | Starts at $1.006/hour (G5.xlarge) | $1.10/hour |
| NVIDIA A100 (40 GB) | Starts at $2.45/hour (P4d.xlarge) | $2.78/hour |
| NVIDIA A100 (80 GB) | Starts at $3.12/hour (P4de.xlarge) | $3.40/hour |
| NVIDIA H100 | Not available | $4.56/hour |
AWS EC2:
AWS EC2 offers flexible pricing models designed to cater to different use cases. On-demand pricing is straightforward and allows users to scale up or down as needed without long-term commitments. However, this flexibility comes at a premium for certain GPU models, particularly high-end ones like the G5 and P4 instances. For example, the G5.12xlarge instance costs $5.672 per hour on-demand, making it suitable for projects requiring immediate scalability but potentially expensive for extended use.
To address cost concerns, AWS provides Reserved Instances (RIs) and Spot Instances. Reserved Instances require upfront payment and commitment periods of one to three years, offering significant discounts of up to 75% compared to on-demand rates. Spot Instances, which utilize unused AWS capacity, can provide savings of up to 90%. However, they come with the caveat of potential interruptions, making them ideal for non-critical or batch processing tasks rather than continuous workloads.
AWS also provides a broad range of GPU models across different regions, ensuring availability and competitive pricing globally. For organizations that prioritize sustained usage and control over costs, Reserved Instances are a clear advantage. Spot Instances add a layer of cost optimization for flexible and interruptible tasks.
Modal:
Modal’s pricing structure emphasizes transparency and simplicity. It adopts a serverless approach, charging users only for active compute time. This eliminates costs associated with idle resources, which is particularly beneficial for workloads with unpredictable or bursty usage patterns. For instance, the NVIDIA H100 on Modal costs $4.56 per hour, aligning closely with AWS’s high-end options but without the need for pre-planning or commitments.
While Modal’s per-hour rates might seem higher than AWS’s Spot Instance prices, the pay-as-you-go model ensures users aren’t charged for unused capacity. This makes Modal an attractive choice for developers focusing on short-term projects, rapid prototyping, or workloads with fluctuating demands. The serverless nature also simplifies budgeting since costs directly correlate with actual usage.
Modal is especially advantageous for AI/ML developers who need quick scalability without managing infrastructure. For example, training a machine learning model or handling bursty data processing tasks can be done cost-effectively without worrying about idle costs. Modal’s pricing also avoids the complexity of managing Reserved or Spot Instances, appealing to users who prefer straightforward billing.
Winner: AWS is better suited for long-term, predictable workloads due to cost-saving options like Reserved Instances and Spot Instances. Modal excels in scenarios requiring short-term, bursty usage or projects with unpredictable workloads, thanks to its serverless, pay-as-you-go model.
Ease of Use
AWS EC2:
Managing AWS Lambda functions and deploying serverless functions with AWS EC2 requires initial setup, configuration, and YAML-based advanced deployment strategies. AWS Lambda supports HTTP requests, allowing developers to run code in response to web requests or other triggers.
However, the process of building and deploying machine learning models or web apps on AWS can be complex and time-consuming, often requiring fine-grained control over the operating system and infrastructure.
Modal:
Modal’s approach to serverless computing removes the need for manual infrastructure management. Developers can use Modal’s seamless Python integration, such as modal.import_app, to deploy ML models, train neural networks, or set up web endpoints with ease.
Unlike AWS EC2, Modal’s serverless functions simplify workflows, allowing users to focus on developing their machine learning models and web apps rather than managing infrastructure. Modal excels at rapid deployment for tasks like training neural networks or handling web requests, making it ideal for fast-paced development environments.
Winner: Modal for ease of use, especially for developers prioritizing simplicity and speed in serverless computing.
Use Cases
AWS EC2:
AWS EC2 is ideal for organizations that require sustained GPU availability and granular control over their infrastructure. It suits a wide range of applications, including gaming, 3D rendering, and training complex machine-learning models.
The flexibility to customize operating system settings and integrate with other AWS services ensures robust support for workloads like web apps and large-scale simulations. For businesses looking for advanced capabilities similar to Google Cloud’s offerings, EC2 provides competitive options to run both traditional and cutting-edge workloads.
Modal:
Modal shines in scenarios requiring quick scalability and minimal infrastructure management. It’s particularly well-suited for AI/ML developers who need to deploy machine learning models, train neural networks, or manage generative AI workloads efficiently.
With features like modal.import_app, it simplifies the process of building web endpoints or handling HTTP requests in a serverless environment. Modal is not just a service for deploying code; it’s an ecosystem optimized for modern development workflows, offering seamless integration with tools and rapid deployment for applications like web apps and machine learning tasks.
Winner: Tie, depending on the specific use case.
Save up to 50% on GPU costs with compared to competitors while enjoying top-tier performance with CUDO Compute’s advanced GPUs. Sign up now!
Additional Features
AWS EC2
AWS EC2 stands out for its feature richness and integration capabilities. It offers a broad selection of GPU models, ranging from entry-level GPUs like the NVIDIA T4 to high-performance options like the NVIDIA A100. This versatility makes it suitable for diverse workloads, including AI, gaming, and graphics rendering. AWS EC2 integrates seamlessly with other AWS services like S3 for storage and RDS for databases, enabling end-to-end cloud solutions.
Advanced networking options, including support for Elastic Fabric Adapter (EFA), provide high-throughput and low-latency communication, making EC2 ideal for distributed machine learning training and HPC workloads. These features give developers extensive control over their infrastructure, allowing them to fine-tune their setups for optimal performance. AWS also supports compliance with industry standards, ensuring secure deployments.
Modal:
Modal takes a different approach by focusing on simplicity and developer-centric features. Its serverless pricing model ensures that users only pay for actual compute time, eliminating costs associated with idle resources. This makes it particularly appealing for developers working on bursty or unpredictable workloads. Modal is optimized for Python-based workflows, offering seamless integration with Python codebases and debugging tools, such as the modal shell, for interactive problem-solving.
Modal’s SOC 2 and HIPAA compliance ensures that applications meet strict security and governance standards. This makes it a reliable choice for industries requiring high levels of data protection, such as healthcare and finance. Modal also simplifies the deployment of any web endpoint and function along with the modal import app, enabling rapid scaling and efficient resource utilization without the need for extensive configuration.
Winner: Modal for simplicity and security; AWS for feature richness and integrations.
Modal vs AWS: The Bottom Line
AWS EC2 and Modal cater to distinct audiences with their cloud GPU services, each excelling in different areas. AWS EC2 stands out for its broad range of GPU models, extensive integrations with AWS services, and options for cost-saving through Reserved and Spot Instances. It’s a go-to solution for organizations requiring sustained GPU performance and fine-grained control over their infrastructure. The ability to deploy resources across multiple regions ensures low latency and compliance, making AWS a powerful choice for enterprises with diverse and long-term needs.
On the other hand, Modal offers a serverless-first approach designed to simplify workflows. Its pay-per-second pricing model eliminates idle resource costs, making it a strong contender for short-term, bursty workloads. Modal’s rapid autoscaling capabilities are particularly advantageous for AI/ML developers, enabling them to deploy machine learning models, run training sessions, or handle dynamic workloads without managing the underlying infrastructure. This ease of use, combined with its focus on Python-based development, positions Modal as an ideal solution for fast-paced development environments.
Ultimately, the choice between AWS EC2 and Modal hinges on specific workload characteristics, budget, and infrastructure preferences. If your focus is on sustained usage, cost optimization through reserved instances, or leveraging a broad ecosystem of cloud services, AWS EC2 is likely the better option. Conversely, if you need scalability, simplicity, and cost-efficiency for short-term or unpredictable workloads, Modal’s serverless architecture is hard to beat. Each platform shines in its respective niche, ensuring there’s a tailored solution for diverse cloud GPU needs.