Baseten vs Modal: Which Offers Better GPU Performance and Value?

Cloud GPUs have completely changed how developers scale AI models. Whether you’re building real-time chatbots, training massive datasets, or deploying complex neural networks, choosing the right GPU service is crucial. But with so many providers promising lightning-fast performance, how do you know which one’s right for you?
Baseten and Modal are two popular names in the cloud GPU world. Both boast high scalability, seamless autoscaling, and developer-friendly workflows. But the devil’s in the details—like the GPU models they offer, the pricing structure, and the performance benchmarks.
In this post, we’ll break down Baseten vs Modal, comparing their cloud GPU services, pricing, and performance features. If you’re debating which provider suits your needs, stick around—we’ve got the insights to help you decide.
Table of Contents
Baseten vs. Modal: GPU Comparison
When comparing Baseten and Modal for cloud GPU services, several key factors emerge: GPU offerings, pricing, performance, developer tools, autoscaling capabilities, and enterprise readiness. Both services aim to optimize high-performance AI inference and workloads but differ in approach and implementation. Let’s break this down comprehensively.
GPU Models and Pricing
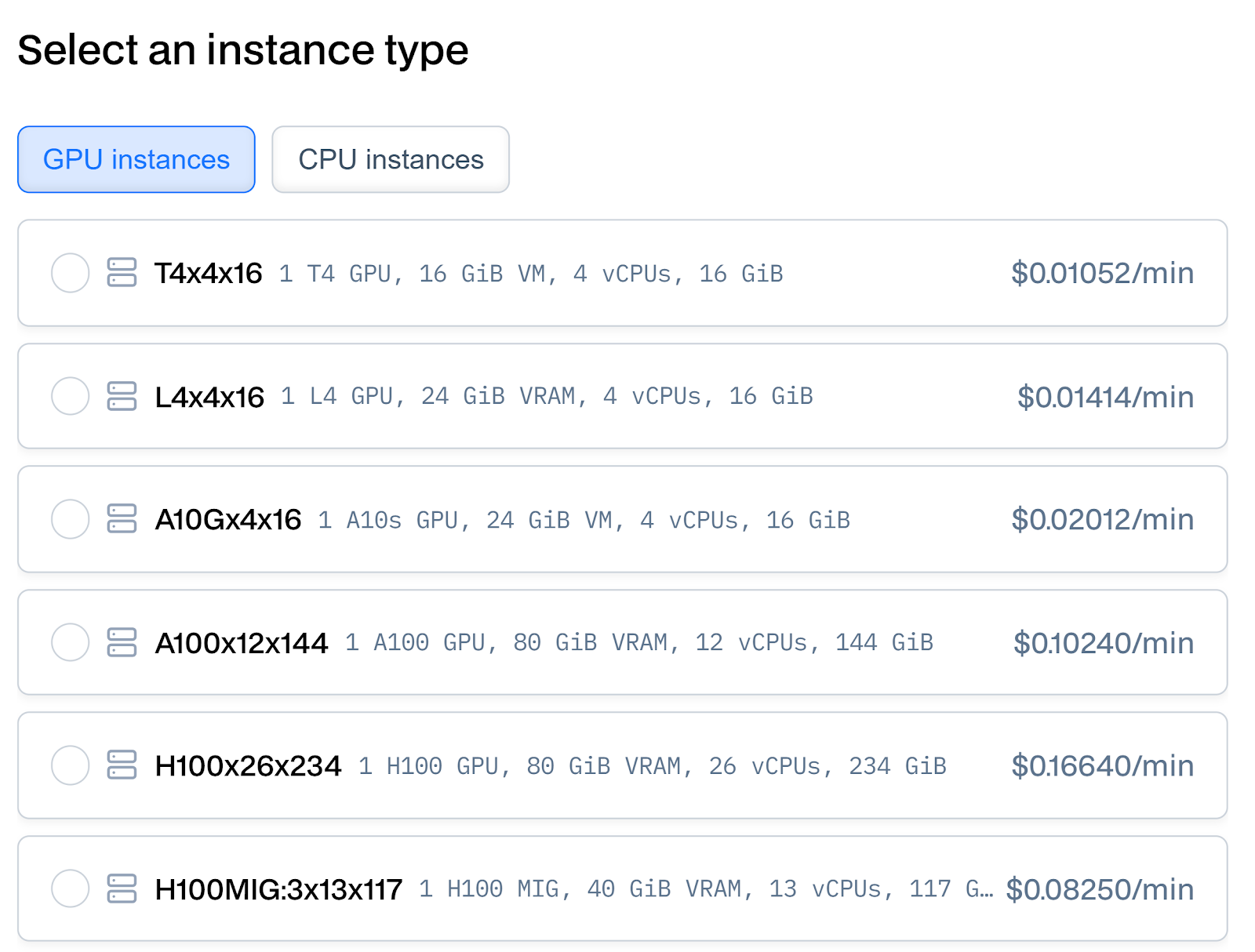
Baseten
Baseten offers a range of GPU options tailored for AI workloads. Here’s a breakdown:
| Instance | GPU | VRAM | vCPUs | RAM | Price per Minute |
| T4x4x16 | NVIDIA T4 | 16 GiB | 4 | 16 GiB | $0.01052 |
| L4x4x16 | NVIDIA L4 | 24 GiB | 4 | 16 GiB | $0.01414 |
| A10Gx4x16 | NVIDIA A10G | 24 GiB | 4 | 16 GiB | $0.02012 |
| A100x12x144 | NVIDIA A100 | 80 GiB | 12 | 144 GiB | $0.10240 |
| H100x26x234 | NVIDIA H100 | 80 GiB | 26 | 234 GiB | $0.16640 |
| H100MIG:3x13x117 | H100 MIG | 40 GiB | 13 | 117 GiB | $0.08250 |
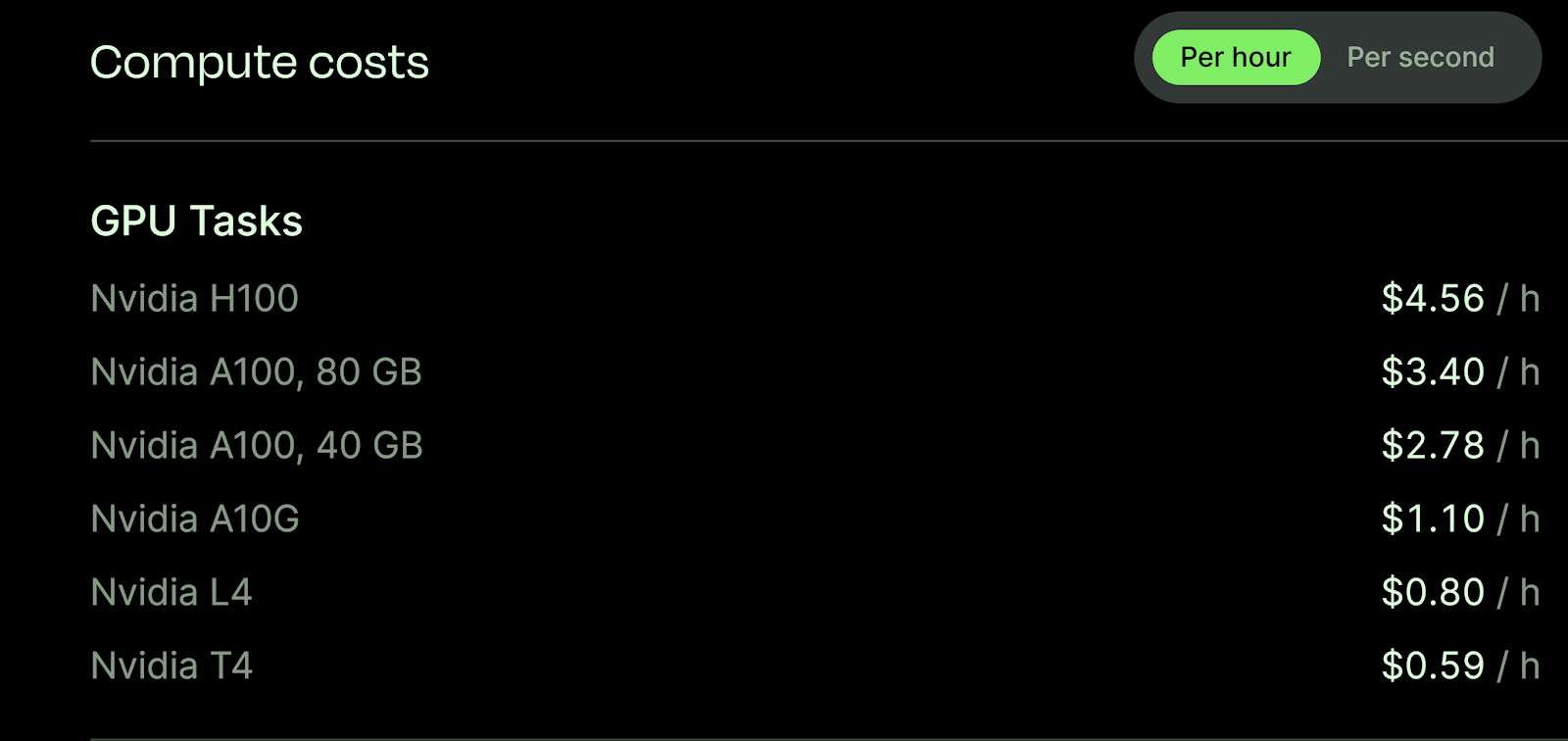
Modal
Modal also provides a robust set of GPU options:
| GPU | VRAM | Price per Hour |
| NVIDIA H100 | 80 GB | $4.56 |
| NVIDIA A100 (80 GB) | 80 GB | $3.40 |
| NVIDIA A100 (40 GB) | 40 GB | $2.78 |
| NVIDIA A10G | 24 GB | $1.10 |
| NVIDIA L4 | 24 GB | $0.80 |
| NVIDIA T4 | 16 GB | $0.59 |
Key Takeaway:
- Baseten’s Pricing Granularity: Charges by the minute, ideal for short-lived tasks. Modal uses an hourly rate but breaks it down into per-second increments, maintaining cost-efficiency for bursts of compute.
- Variety and Cost-Effectiveness: Modal’s pricing for the A100 and H100 is lower per unit time compared to Baseten, especially when running extended jobs. However, Baseten offers smaller instance types like T4, providing flexibility for less resource-intensive tasks.
Save significantly with CUDO Compute’s long-term plans, with hourly GPU rates as low as $0.30, perfect for startups and enterprises alike. Sign up now!
GPU Performance
Baseten
Baseten’s GPU performance focuses on delivering exceptional throughput and minimal latency, making it a strong contender for real-time, latency-sensitive applications. With a throughput of up to 1,500 tokens per second, Baseten is optimized for demanding use cases like chatbots, virtual assistants, and live translation services. These applications rely on immediate responsiveness, and Baseten ensures they meet user expectations without delays.
One of Baseten’s standout features is its fast cold start capability. The platform’s optimized pipeline — including streamlined steps for container initiation, model caching, and weight loading — ensures even large models like Stable Diffusion XL are ready for inference in under two seconds. This reduces downtime and enhances user experience, especially for applications requiring on-demand scaling.
Baseten further enhances efficiency through TensorRT-LLM, which optimizes model inference to reduce memory usage while increasing throughput. This makes it particularly effective for large language models and other GPU-intensive tasks, ensuring they perform efficiently without overloading hardware. By maximizing GPU utilization and minimizing waste, Baseten provides robust support for applications in natural language processing (NLP), computer vision, and other domains that rely heavily on real-time performance.
Modal
Modal takes a distinctive approach to GPU performance, leveraging its Rust-based lightweight container stack for rapid provisioning and scalability. This architecture ensures that GPUs are allocated and released with minimal overhead, a critical advantage for applications that require dynamic resource allocation.
Modal’s cold start optimization is tailored to generative AI and inference workflows, allowing large models to load their weights quickly. This feature is particularly beneficial for developers working with models like GPT, Stable Diffusion, or custom architectures, as it minimizes delays during model initialization. For businesses handling workloads with unpredictable spikes, this ensures they can adapt instantly without sacrificing performance.
A key strength of Modal lies in its batch processing capabilities, which excel at parallelism for large-scale workloads. Modal’s infrastructure can scale seamlessly to thousands of GPUs, making it a powerful solution for high-volume tasks such as training, fine-tuning, or processing vast datasets. This makes Modal ideal for companies focused on large-scale experimentation, data pre-processing, or rendering-intensive operations.
Key Takeaways:
- Baseten shines in interactive, low-latency use cases, such as live inference.
- Modal’s infrastructure is highly suited for heavy-duty batch workloads and large-scale training jobs.
Choose from NVIDIA and AMD GPUs, like the H100 and A100, from CUDO Compute for cost-effective, scalable solutions that suit your needs. Sign up now!
Autoscaling
Baseten
Baseten’s autoscaling capabilities are designed for performance and cost-efficiency, making it an excellent choice for teams handling fluctuating workloads. Its Effortless Scaling feature automatically adjusts resources horizontally in response to incoming traffic. Whether your application requires a single instance or thousands of replicas, Baseten ensures that models scale seamlessly to meet demand.
For cost-conscious teams, Baseten’s scaling framework includes intelligent cost management. When demand drops, the system scales down to zero, ensuring that you only pay for the compute you actively use. This approach makes Baseten ideal for applications like chatbots, recommendation systems, and real-time data processing, where traffic volumes can vary significantly. Its infrastructure also supports blazing-fast cold starts, so scaling up from zero doesn’t compromise performance.
By combining responsive autoscaling with fine-grained cost control, Baseten provides an optimized solution for companies looking to scale their inference workloads efficiently.
Modal
Modal takes a slightly different approach, leveraging its serverless architecture to deliver highly dynamic autoscaling. Unlike traditional autoscaling methods, Modal’s serverless framework inherently eliminates idle resource costs by ensuring that resources are only provisioned when tasks are running. This model is particularly suited for bursty workloads, such as batch processing, generative AI, or experimentation, where the volume of tasks can change rapidly.
Modal also integrates its scaling capabilities seamlessly into its Python-based framework. Developers can implement and manage scaling directly within their code, reducing the complexity of setup and configuration. This feature makes Modal a developer-friendly platform that simplifies resource management without sacrificing performance.
Key Takeaway:
- Both providers handle autoscaling well, but Baseten offers fine-tuned control for production-grade deployments, while Modal emphasizes simplicity and scalability for diverse workloads.
Developer Experience
Baseten
Baseten prioritizes a seamless and efficient workflow for developers, starting with Truss, its open-source model packaging standard. This tool supports popular frameworks like PyTorch, TensorFlow, and TensorRT, making it easier for developers to package and share models consistently. Deploying a model is remarkably straightforward with Baseten’s streamlined deployment process: a single command can turn a model into a production-ready API, significantly reducing setup time and effort.
For ongoing operations, Baseten provides robust observability features, allowing developers to monitor critical metrics such as inference counts, response times, and GPU utilization in real time. These tools ensure that developers can quickly identify and address bottlenecks, optimize performance, and maintain reliability. Whether you’re deploying a chatbot, a recommendation engine, or an image classification model, Baseten’s developer-centric features make the transition from development to production both simple and efficient.
Modal
Modal’s developer tools are designed for flexibility and precision. Its support for custom containers ensures that developers can bring their preferred environments into production without restrictions. Whether you’re running specialized frameworks or using niche libraries, Modal accommodates these needs with ease.
Debugging is also a standout feature of Modal. The built-in Modal shell allows for interactive debugging, complete with support for setting breakpoints. This feature reduces the time spent troubleshooting issues, making it easier to ensure error-free deployments. Additionally, Modal offers advanced job scheduling capabilities, including retries, cron jobs, and timeout settings. These scheduling options provide developers with fine-grained control over how tasks are executed, ensuring efficient resource utilization and reliable performance.
Key Takeaway:
- Baseten focuses on enterprise-grade workflows and observability tools, while Modal prioritizes developer flexibility and rapid iteration.
Effortlessly deploy AI, rendering, or ML models on CUDO Compute’s GPU infrastructure, designed to accelerate your workflows. Sign up now!
Enterprise Readiness
Baseten
Baseten ensures enterprise-grade infrastructure tailored for data teams and organizations deploying ML models in critical environments. It stands out with SOC 2 Type II and HIPAA compliance, making it an excellent choice for companies with stringent data protection and privacy standards. For organizations prioritizing security, Baseten offers single tenancy, ensuring greater isolation for sensitive ml models and data workflows.
Furthermore, its ability to support custom hosting on private or hybrid clouds allows businesses to align their deployments with specific regulatory or operational needs. This flexibility is invaluable for enterprises handling sensitive data workflows or operating within industries with strict compliance requirements, such as healthcare and finance.
Modal
Modal brings robust security features to the table with its multi-tenancy isolation powered by gVisor, a secure application kernel for containers. This technology provides excellent security for multi-tenant environments, making Modal suitable for enterprises seeking scalable and secure ML model deployment solutions.
The platform also supports global deployment with region-specific compliance, ensuring any data team can operate within regulatory frameworks across diverse geographic locations. Additionally, Modal’s enterprise-grade SSO integration via Okta simplifies access management, streamlining authentication for data teams working across complex projects.
Key Takeaways:
- Both platforms are enterprise-ready, but Baseten offers more tailored hosting options for organizations with strict compliance requirements.
Use Cases
Baseten
Baseten is a standout choice for data scientists, machine learning engineers, and data teams focused on companies scaling inference in production. Its strength lies in interactive applications that require real-time responsiveness, such as chatbots, virtual assistants, and natural language processing (NLP) services.
The platform excels in delivering low-latency, high-throughput model serving, making it perfect for machine learning models used in conversational AI or live translation tasks. Additionally, Baseten offers cost-efficient autoscaling, ensuring businesses only pay for the GPU resources they use. This makes it an attractive option for model deployment workflows where cost and performance are equally critical.
Modal
Modal caters to the needs of machine learning engineers, data engineers, and data scientists working on computationally heavy tasks like training machine learning models, fine-tuning custom models, or processing structured data at scale. Its optimized infrastructure shines in generative AI applications such as building and refining models like GPT and Stable Diffusion.
Modal’s ability to handle large-scale data pipelines, data workflows, and high-volume batch processing is invaluable for organizations tackling intensive data science projects. The serverless GPU space provided by Modal ensures seamless scaling and eliminates idle resource costs, making it ideal for teams with fluctuating workloads.
Key Takeaways:
- Choose Baseten for inference-heavy applications needing low latency.
- Opt for Modal when handling training, batch processing, or bursty workloads.
Baseten vs. Modal: Which one should you go for?
The choice between Baseten and Modal hinges on workload type, cost sensitivity, and operational priorities.
- Baseten is the better choice for enterprises needing high-performance inference, stringent compliance, and seamless integration into production pipelines.
- Modal is ideal for developers focused on training, experimenting, or handling large-scale batch tasks with flexible, cost-effective scaling.
Ultimately, the decision boils down to specific use cases and budgetary constraints. Both providers offer robust solutions, making either a valuable addition to AI workflows.