

Amazon EC2 P3 vs G5: Which AWS Instance Fits Your GPU Workload?

The EC2 P3 and G5 instances are the big guns for machine learning and high-performance computing (HPC) when it comes to GPU cloud services on AWS. Each has its strengths and can bring serious power to different workloads. But with two powerful options to choose from, you have a big question: which one is for you?
EC2 P3 and G5 instances bring NVIDIA Tensor Core GPUs to the table, but the GPU models, performance, and price are very different. We’re going to get into the details, comparing everything from machine learning to the cost of scaling your workloads. Whether you want maximum speed or the best bang for your buck, understanding these two instances will help you make a decision.
Affiliate Disclosure
We are committed to being transparent with our audience. When you purchase via our affiliate links, we may receive a commission at no extra cost to you. These commissions support our ability to deliver independent and high-quality content. We only endorse products and services that we have personally used or carefully researched, ensuring they provide real value to our readers.
CUDO Compute delivers the flexibility and power to scale your operations, making it the go-to alternative to Amazon EC2. Sign up now!
For a deeper understanding of CUDO Compute, take a look at this informative video:
Table of Contents
Amazon EC2 P3 vs G5: Detailed Comparison
GPU Comparison: NVIDIA V100 vs. NVIDIA A10G
The biggest difference between Amazon EC2 P3 and G5 instances comes down to the GPU models they use: NVIDIA V100 on EC2 P3 instances and NVIDIA A10G on EC2 G5 instances. Both are designed for different workloads and excel in different areas.
NVIDIA V100 Tensor Core (EC2 P3 Instances)
- Architecture: Volta
- Memory: 32 GiB per GPU
- Compute Performance: Up to 1 petaflop of mixed-precision performance
- Use Case: High-performance computing (HPC), advanced deep learning, large-scale machine learning training
The NVIDIA V100 is a powerhouse GPU optimized for demanding machine learning workloads and HPC applications. It’s built to handle intensive tasks like training deep neural networks or running complex simulations. EC2 P3 instances are specifically built for those users who need extreme performance to train massive machine learning models in less time.
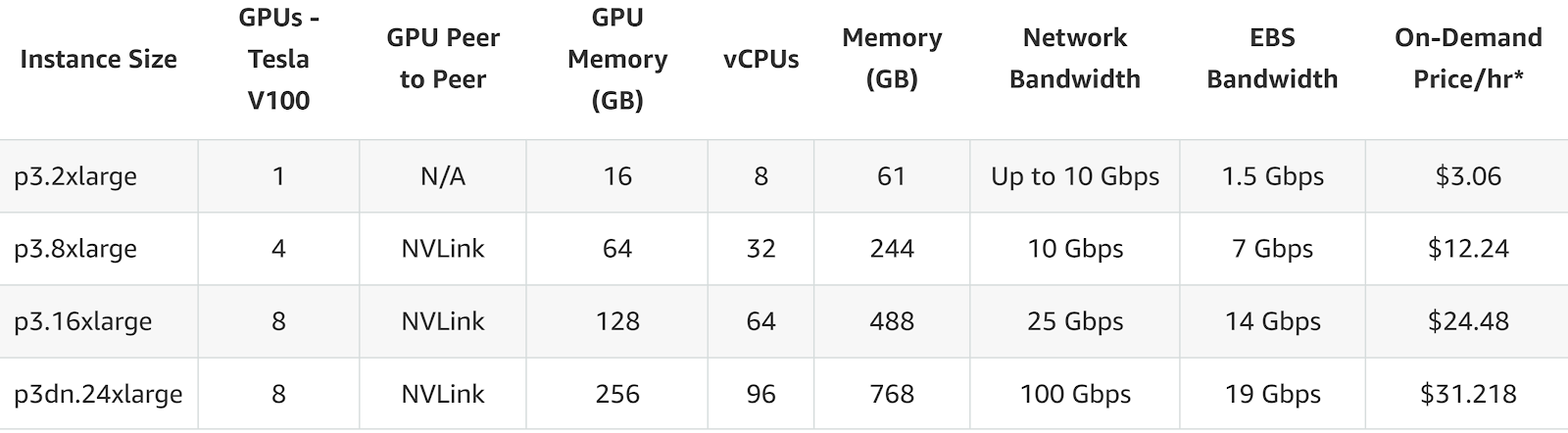
You get up to 8 V100 GPUs per instance, interconnected via NVLink, which enhances GPU-to-GPU communication speed—crucial when scaling distributed machine learning tasks.
Example use case: Training a ResNet-50 image classification model, which traditionally takes days, can be reduced to minutes with EC2 P3 instances.
NVIDIA A10G Tensor Core (EC2 G5 Instances)
- Architecture: Ampere
- Memory: 24 GiB per GPU
- Compute Performance: Up to 250 TOPS (Tera Operations per Second) for AI inference workloads
- Use Case: Machine learning inference, graphics-intensive applications (gaming, video rendering, remote workstations)
The A10G GPUs on EC2 G5 instances are aimed at both machine learning inference tasks and high-end graphics workloads. These GPUs perform better than the previous generation (G4) and offer cost-efficient solutions for moderately complex ML models. Their ray-tracing cores make them ideal for rendering realistic scenes faster than normal GPUs, while their compute power handles moderately-sized ML models.
While EC2 G5 can’t match the sheer raw computational power of the V100 on EC2 P3 instances, it’s highly efficient to deploy machine learning models or produce high-fidelity graphics applications.
Example use case: If you’re running a video rendering service or real-time gaming platform, EC2 G5 is the sweet spot. It’s optimized for both price and performance in these areas.
CUDO offers NVIDIA and AMD GPUs, ensuring you can select the best hardware for your specific computational needs. Sign up now!
Pricing Comparison
When choosing your EC2 instance for your project, pricing is a big factor. AWS has many pricing options depending on how much you are willing to commit and what kind of workload you have.
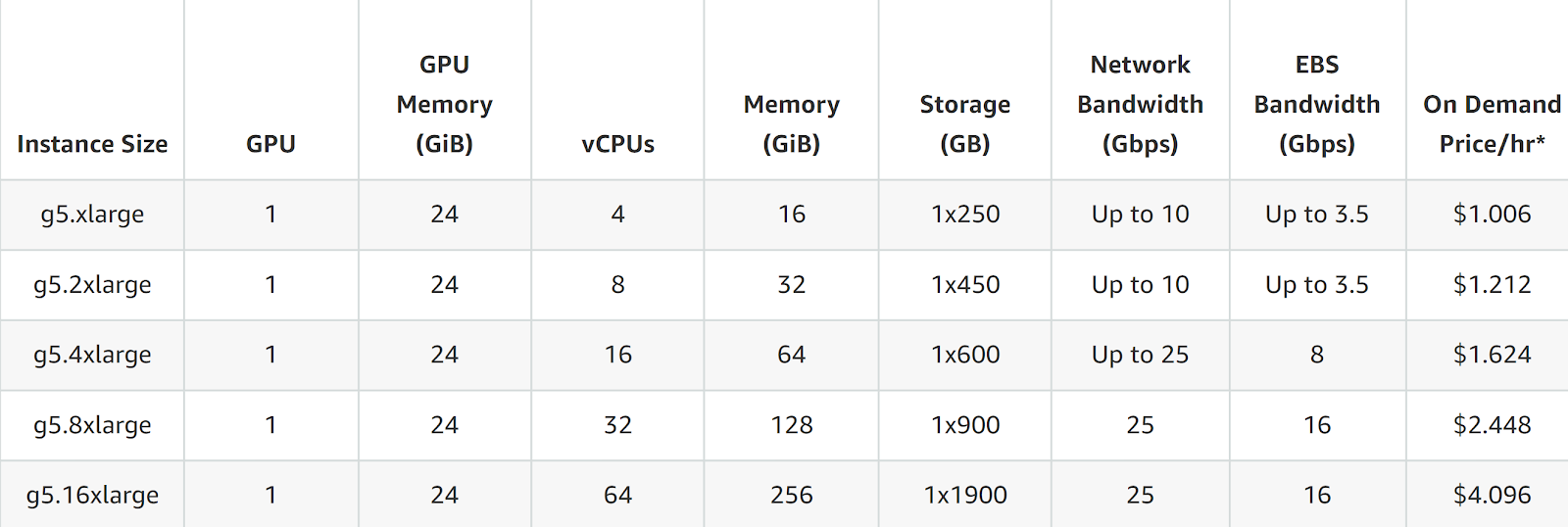
Let’s break it down between the P3.16xlarge (with NVIDIA V100 GPUs) and the G5.16xlarge (with NVIDIA A10G GPUs) and we’ll go into more detail on each pricing structure, including on-demand and reserved instances for different terms.
| Instance Type | On-Demand Price (per hour) | 1-Year Reserved Price (per hour) | 3-Year Reserved Price (per hour) |
| P3.16xlarge (V100 GPU) | $24.48 | $15.91 | $8.39 |
| G5.16xlarge (A10G GPU) | $4.096 | $2.458 | $1.638 |
On-Demand Pricing
- P3.16xlarge: $24.48/hour
If you need the maximum GPU power on-demand, the P3 instance is priced way higher. This makes sense for companies or individuals that do large-scale tasks like deep learning model training, scientific computations or complex simulations. The V100 GPU is powerful but at a high cost. - G5.16xlarge: $4.096/hour
The G5 instance is more affordable for on-demand. It’s only 16.7% of the P3. For many workloads, especially inference, graphics rendering, or gaming, the G5 is great performance at a fraction of the cost.
1-Year Reserved Pricing
- P3.16xlarge: $15.91/hour
A 1-year reservation brings the price down by over 35% making it more viable for long-term projects that still need high-performance GPUs. But even with this discount, the P3 is still a heavy hitter in terms of cost. - G5.16xlarge: $2.458/hour
The 1-year reserved price for the G5 is a big cost reduction. This is 40% cheaper than on-demand pricing, making it a great choice for projects that need a mid to long term GPU solution. At under $2.50/hour, you’re looking at high-performance GPU processing at a price that’s much more manageable.
3-Year Reserved Pricing
- P3.16xlarge: $8.39/hour
The 3-year reservation brings the price down to $8.39/hour from $24.48 on-demand. That’s a 66% discount! If you’re in for the long haul and need these powerful GPUs for years to come, this reserved pricing makes P3 more wallet-friendly. - G5.16xlarge: $1.638/hour
For the G5, the 3-year reserved price is down to $1.64/hour which is 60% cheaper than on-demand. It’s no wonder the G5 is a favorite among developers and businesses that need to optimize their costs for GPU-based workloads especially when the project timeline is long-term. It’s a smart choice if you plan to use GPU compute and memory resources for years.
With on-demand pricing starting as low as $0.30/hr, CUDO Compute provides cost-effective GPU rental for any project. Sign up now!
P3.16xlarge vs G5.16xlarge: Performance Breakdown
When comparing the P3.16xlarge and G5.16xlarge, understanding how each instance handles different workloads is essential. Each has strengths suited to specific tasks, but depending on your needs, one might drastically outperform the other.
Machine Learning Training
The P3.16xlarge is far better for machine learning training compared with the G5.16xlarge, especially for very large and complex models like GPT-3, computer vision, or large-scale convolutional neural networks (CNNs). With the NVIDIA V100 GPU, it has 16 GB of HBM2 memory and much higher floating point precision which is important for training models that require large batch sizes and high accuracy. The V100’s tensor cores are designed to accelerate deep learning training. So the P3 is great for machine learning customers who need precision and heavy data processing.
On the other hand, the EC2 G5.16xlarge with A10G GPU is a step down for large-scale training. It doesn’t have the same performance as the P3, especially when you’re working with models that need more GPU memory or compute. But it’s still good for moderately complex models. If you’re training medium-sized models and your workload doesn’t require the highest precision the G5 might be a more cost-effective option.
Inference
The G5 instances deliver high performance and are way better for machine learning inference compared to the P3 instances. They are great for inference because of their power efficiency and solid GPU for a fraction of the price. The A10G may not be as powerful as the V100 but it’s enough for most inference workloads without breaking the bank. If your use case is deploying models for real-time inference or handling multiple concurrent requests the G5 will give you good results without overpaying for unused horsepower.
In contrast, the EC2 P3 is better for inference for very large and computationally intensive models. If you’re working with ultra-high-end deep learning models that require extreme performance the P3 with V100 will still beat the G5. But for most inference workloads the G5 is more than enough.
Graphics and Rendering
In graphics rendering and gaming the EC2 G5 wins. The A10G GPU has NVIDIA RTX technology and specialized ray tracing cores which are designed for real-time ray tracing and rendering. These are perfect for workloads like 3D rendering, virtual reality applications, and even game development. If you’re working on projects that require real-time rendering or graphical computation the G5 is a great choice.
The P3.16xlarge doesn’t do as well for these types of tasks. It can do them but it’s not optimized for real-time graphics or rendering like the G5 is. The V100 is focused more on deep learning and HPC workloads than graphical tasks so if your workload involves significant graphics processing the G5 is the clear winner.
In the end, it comes down to the type of workload you’re running. For high-end ML training and extreme precision, the P3 with V100 is unbeatable. But for most other workloads—especially inference and graphics-heavy work—the G5’s A10G is a great balance of price and performance and is the better choice for many users.
Price-to-Performance Breakdown
While the EC2 P3 instances provide unparalleled raw performance for demanding tasks like training AI models and HPC, their high costs can be justified only if you’re pushing these workloads to their limits. For companies running machine learning pipelines that include massive neural networks, the P3 with its V100 will pay off.
The EC2 G5 instances, meanwhile, are excellent for price-conscious users who need solid GPU power without the steep costs. It’s perfect for workloads like inference and high-end graphics processing. You get nearly 75-80% of the performance for a fraction of the cost. For many developers and teams working with AI/ML, gaming, or graphics-based workloads, the G5 is more than enough and at an incredibly competitive price.
When choosing between the P3.16xlarge and G5.16xlarge instances, the decision comes down to what’s more important to you: raw GPU power or cost-effectiveness. If you need the full potential of V100 GPUs for deep learning, the P3 is your go-to but at a high price. If you’re looking for a more balanced approach with a solid price-to-performance ratio, the G5.16xlarge with A10G GPUs is hard to beat.
CUDO’s flexible GPU plans allow you to save money over time, with long-term discounts for 1, 3, and 6-month rentals. Sign up now!
Compute Power: vCPUs and RAM
P3 Instances
P3 instances offer configurations with up to 96 vCPUs and 768 GB of RAM (on the p3dn.24xlarge). The higher vCPU count, combined with the powerful NVIDIA V100 GPUs, makes P3 instances excellent for compute-heavy tasks that require large-scale parallel processing.
- Top Configuration (P3dn.24xlarge):
- vCPUs: 96
- RAM: 768 GB
- Network Bandwidth: 100 Gbps
G5 Instances
G5 instances provide a slightly lower range in terms of vCPUs but are still quite powerful for most tasks. They offer up to 192 vCPUs and 768 GB of RAM, which matches the memory of P3 instances but is backed by the slightly less powerful A10G GPUs.
- Top Configuration (G5.48xlarge):
- vCPUs: 192
- RAM: 768 GB
- Network Bandwidth: 100 Gbps
While G5 instances offer double the vCPUs of P3 instances, the lower GPU performance might be a limiting factor for those who need high-performance GPUs for training large ML models.
Network Bandwidth
Both P3 and G5 instances support 100 Gbps network bandwidth which is required for distributed machine learning and high-performance computing. So both instances can handle large-scale multi-node training or rendering without data transfer bottlenecks.
P3 Instances: P3 instances, especially p3dn.24xlarge are optimized for distributed machine learning with 100 Gbps network bandwidth. Good for scaling out workloads across multiple instances for large-scale deep learning model training.
G5 Instances: 100 Gbps networking throughput enabling fast data transfer and large video files or moderate ML model training.
Storage
P3 Instances
P3 instances feature up to 1.8 TB of local NVMe-based SSD storage (on p3dn.24xlarge), which is ideal for storing large datasets and reducing latency in data access during compute-intensive tasks.
G5 Instances
G5 instances offer up to 7.6 TB of local NVMe-based SSD storage, significantly more than P3 instances. This is especially useful for storing large datasets locally during training or inference and for graphics-intensive applications where quick access to large files is necessary.
Save big with discounted rates on long-term GPU usage, including savings of up to $2,795 when choosing extended plans with CUDO Compute. Sign up now!
Use Cases
Machine Learning Training
- EC2 P3 Instances: Due to the V100 GPU’s superior performance, P3 instances are a better choice for large-scale ML training. The 32 GB of memory per GPU, high Tensor core count, and NVLink for GPU communication make them ideal for tasks like deep learning, natural language processing, and high-precision simulations. Customers looking to train complex models at scale will benefit from the raw power of P3 GPU instances.
- EC2 G5 Instances: G5 instances are suitable for moderately complex ML training workloads, offering a good balance between performance and cost efficiency. With A10G GPUs, they are a good fit for smaller or less complex models.
Machine Learning Inference
- EC2 P3 Instances: P3 instances are overkill for inference tasks that don’t require the full power of the V100 GPU.
- EC2 G5 Instances: G5 instances shine in inference workloads. Their lower price and ample GPU memory (24 GB per A10G GPU) make them a great option for deploying inference pipelines, especially those involving NLP or recommendation systems.
Graphics-Intensive Applications
- EC2 P3 Instances: P3 instances, with NVIDIA V100 GPUs, aren’t specifically designed for graphics workloads, although they are more than capable of handling some 3D rendering tasks.
- EC2 G5 Instances: G5 instances are the clear winner for graphics-heavy applications like video rendering, game development, and virtual workstations. The A10G GPUs are built for increased graphics performance offering ray-tracing cores and they support NVIDIA RTX technology as well. EC2 G5 instances deliver high-quality virtual workstations and are the better choice for customers with high graphical demands.
Elastic Fabric Adapter (EFA)
Both P3 and G5 instances can use Elastic Fabric Adapter (EFA), but the use case differs.
- EC2 P3 Instances: EFA significantly improves performance in distributed ML training by allowing instances to scale to thousands of GPUs. This feature is critical for workloads where multiple GPUs across different instances need to communicate efficiently.
- EC2 G5 Instances: While EC2 G5 instances also support EFA, the feature is more valuable in the EC2 P3 ecosystem due to the larger focus on distributed training of deep learning models.
Easily launch an instance with CUDO Compute and deploy complex workloads like rendering and AI model training in just minutes. Sign up now!
Amazon EC2 P3 vs G5: Which One Should You Choose?
- Choose EC2 P3 Instances if:
- You’re working with large-scale ML training tasks, especially deep learning models.
- You need the highest performance and are willing to pay for it.
- Your application requires high throughput, massive parallelism, and extensive GPU memory.
- Choose EC2 G5 Instances if:
- You need a cost-efficient option for moderately complex ML tasks or ML inference.
- You are working with graphics-intensive applications like rendering, game development, or virtual workstations.
- You want a balance between cost and performance, especially for smaller-scale or single-node ML models.
In essence, P3 instances are for those who need top-tier performance at a premium price, while G5 instances offer a cost-effective solution for moderately complex workloads, especially in graphics and machine learning inference.
Amazon EC2 P3 vs G5: Frequently Asked Questions
What is the difference between EC2 P series and G series?
The EC2 P series, like EC2 P3, is for large-scale machine learning (ML) training and high-performance computing (HPC) with NVIDIA V100 GPUs. The G series, like G5, is for ML inference, graphics rendering, and virtualized workstations with NVIDIA A10G GPUs and better price performance for moderate workloads.
What are G5 instances?
G5 instances are Amazon EC2 instances powered by NVIDIA A10G GPUs. They are for graphics-intensive workloads, ML inference, gaming, and virtual desktops. EC2 G5 instances are a balance of performance and cost, good for real-time rendering, video processing, and deploying ML models in production.
What is a good use case for Amazon EC2 G5 instances?
G5 instances are good for real-time graphics rendering. Their NVIDIA A10G GPUs with ray-tracing cores are great for 3D rendering, VR, and game development. With Nvidia gaming drivers they are also good for ML inference and video transcoding, a cost-effective solution for moderate workloads that need graphical or computational power.
Whether you’re running large-scale simulations or AI inference tasks, CUDO Compute provides powerful, affordable GPU options tailored to your needs. Sign up now!





